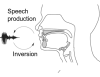
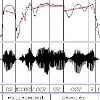
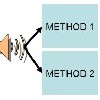
Automated Audio Captioning
Context In recent years, new deep learning systems have been significantly improved for text generation, processing and understanding, leading to the use of free-form text as a global interface between humans and machines. In sound event recognition, most of the tasks are using a predefined set of classes, but human natural language can contain much more information, which could improve