Prosody Modelling
Context
Prosodic features carry a substantial part of the language identity that may be sufficient for humans to perceptually identify some languages. Among these supra-segmental features, intonation is very promising both for linguistic and automatic processing purposes. However, intonation modelling is difficult, both in terms of theoretical definition and automatic processing. We propose here some prosodic modelling approaches that bring pretty good results in the filed of automatic language identification.
Overview
We present here an approach of automatic rhythm modelling with an approach that requires no phonetically labelled data. Using a vowel detection algorithm, rhythmic units somewhat similar to syllables and called pseudo-syllables are segmented.
Pseudo-syllabe decomposition
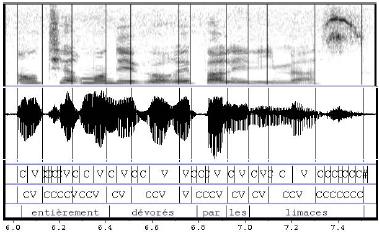
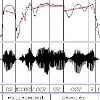
Figure 1. Example of Pseudo Syllable decompositon
We have proposed the concept of Pseudo-Syllable decomposition of the sugnal in order to deals with the constraints of automatic and multilingual modelling for Language Identification. Figure 1 shows the result of the automatic segmentation, vowel location, and vocal activity
detection on a French recording of the MULTEXT database. The sentence is:“[les choux avaient été] entièrement devorés par les limaces.” “#” labels are for nonactivity segments, “V” are for vocalic segments, and other segments are labeled “C.” Word boundaries are displayed for illustration purposes. in layer 1 the spectrogram of speech, layer 2 the speech signal, layer 3 the results of an automatic segmentation in Vowels and Non Vowels segments, layer 4 the Pseudo-Syllable segmentation. Consecutive “C” segments are gathered until a “V” segment is found. See Pseudo-Syllable page for futher explanations on the method.
Prosody coding
In order to model short term prosody, some processes are done in order to extract pertinent parameters.
Baseline computing and coding
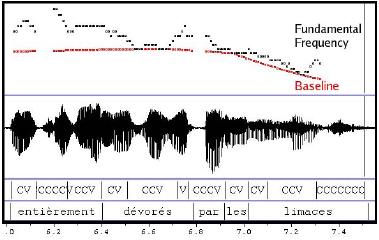
Figure 2. Baseline (red) Decompositon of Fundamental Frequency
The baseline extraction consists in finding all the local minima of the F0 contour, and linking them. Then, the baseline is labeled in terms of U(p), D(own), and #(silence or unvoiced). To find local minima, the sound file is automatically divided into “sentences,” defined here as intervals between silent segments of duration over 250 ms. The linear regression of the F0 curve is then computed on each sentence. Then each part of the curve under the linear regression is used to find a unique minima. Successive minima are linked by linear approximation. An
example of a resulting baseline curve is displayed in Fig. 2. The slope of the regression is used to label the baseline. We use one label per pseudosyllable. Labels are “U” for a positive slope and “D” for a negative slope. Unvoiced pseudosyllables (less than 70% voiced in duration) are labeled “#.”
Residue Approximation and Coding
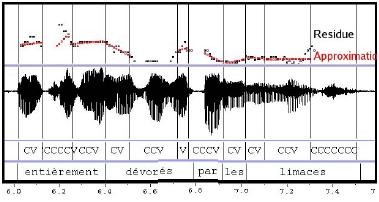
Figure 3. Fundamental Frequency Residue and his approximation (red)
The baseline is subtracted from the original contour. The resulting curve is called residue (Fig. 3). This residue is then approximated for each segment by a linear regression. The slope of the linear regression is used to label the movement on the unit, according to three available labels (Up, Down, and Silence).
Energy Coding
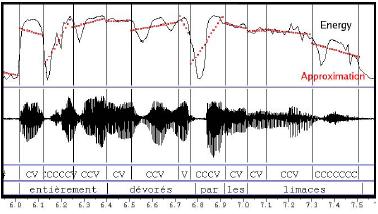
Figure 4. Energy approximation
The energy curve is approximated by linear regressions for each considered units (subphonemic segments or pseudosyllables) (Fig. 4). The process is the same as the one used for the residue coding. As there is no segment with no energy, only two labels are used: Up and Down.
Duration Coding
Duration labels are computed only for the subphonemic segment units. The labels are assigned considering the mean duration of each kind of segment (vocalic, consonantic, or silence). If the segment to label is a vocalic segment with a duration above the mean vocalic segments duration computed on the learning part of the corpus, it is labeled “l” (long), If the current vocalic segment duration is below the mean, the “s” (short) label is then used.
Short-term and Long-term Modelling
To model the prosodic variations, classical n-gram language modeling are used. For each system (long and short-term modeling) each language is modeled by a n-gram model during the learning procedure. During the test phase, the most likely language is picked according to the model which provides the maximum likelihood. For the long-term models, this modeling is applied at the pseudosyllable level, and n-grams are learnt using baseline labels, eventually combined with energy labels coded at the pseudosyllable scale. The short-term models are learnt using the subphonemic segmentation, and using the residue labels, optionally combined with energy and duration labels. For each segment, the label is then composed of three symbols.
Applications
Contributors
Main publications
- Jean-Luc Rouas. Caractérisation et identification automatique des langues. Thèse de doctorat, Université Paul Sabatier, mars 2005
- Jean-Luc Rouas, Jérôme Farinas, François Pellegrino, Régine André-Obrecht. Rhythmic unit extraction and modelling for automatic language identification. Dans : Speech Communication, Elsevier, Vol. 47 N. 4, p. 436-456, 2005.