Acoustic-to-articulatory Inversion
Context
The aim of acoustic-to-articulatory inversion is to recover the vocal tract shape, knowing the acoustics pronounced. This recovery is done by estimating the position of flesh points located on lips, tongue, jaw, and sometimes velum. In our case, 6 captors are positionned on: upper lip, lower lip, jaw, front tongue, middle tongue and back tongue.
System Overview
First, an acoustico-articulatory model is trained, modelling the link between the acoustics and the corresponding articulation. Then, for a given an sequence of acoustic vectors, the articulatory trajectory is generated using this model. The global scheme is presented on figure 1.
For the model training, the originality of our method is to use a unsupervised Hidden Markov Model training.
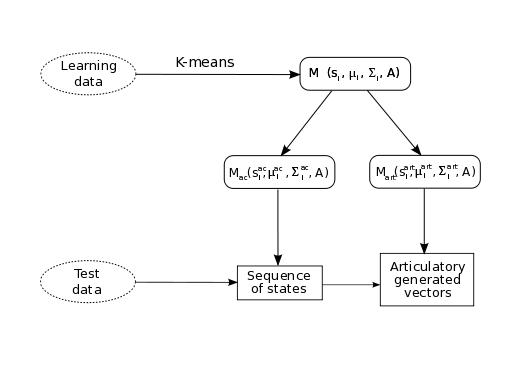
Figure 1: Global scheme of the inversion method
Unsupervised HMM training
We chose to model the link between acoustic and articulatory by a Hidden Markov Model (M on figure 1), in order to take into account the temporal aspect of speech. However, we would like to be independant of any manual annotation, and to mix the HMM approach with a statistical approach (GMM), as both have proved to be efficient. We therefore train a HMM with an unsupervised way. The training is done as described below:
- The training vectors are clustered with an unsupervised algorithm, resulting into Q classes. Each class is assimilated to a state i of the global HMM. Each training vector is therefore assigned a posteriori to a state and labelled.
- The probability density of each state i, is modeled by a Gaussian distribution N(μi, Σi). This distribution is estimated with the training vectors assigned a posteriori to the state i.
- The transition matrix A is classically empirically estimated by counting the number of occurrences of the transitions between states, a transition between two states being a transition between two vectors a posteriori assigned to these states.
Articulatory vectors generation
In the generation process, only the acoustic data are available, the articulatory vectors must be generated. We therefore need to split the acosutic-articulatory model in two “submodels”, which represent respectively the acoustic part (Mac) and the articulatory part (Mart) of the global model M.
The acoustic signal is decoded using the acoustic model, which gives a sequence of states. This sequence of states is then transposed in the articulatory model, leading the the generation of the articulatory vectors.
Applications
Augmented speech: Hearing-impaired persons are known to use lip reading to help their speech understanding. Studies have shown that the knowledge of the position of the tongue and the velum also improve the comprehension.
A help for foreign languages learning: The aim is to show to a student studying a foreign language what was his pronounciation of a sentence, and what is the correct pronounciation of the same sentence. These two pronounciations are presented through a virtual speaking head.
Projects
This work is part of the french ARTIS project.
Contributors
- Hélène Lachambre
- Lionel Koenig
- Régine André-Obrecht (contact)