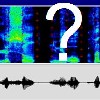
Shot Boundaries Detection
Context Nearly all methods of audio or video segmentation perform with a priori knowledge. These approaches are based on a spatial-temporal modelling of the content and use decision rules. Currently, it is the only way to reach the semantic quality required by search engines. But only recording collections highly structured, such as broadcast videos of news and sports programmes, and