
Audio Video Characters Labelling
Context
Many works were carried out on the audiovisual content characterization, and particularly on person detection. The majority of these studies are mono media and allow the detection of a person either by his visual appearance in a frame (like a face) or by his voice. More recent works start video content analysis by integrating both acoustics and visual features, which are the two inseparable parts of a video. The goal of these applications is to find, starting from voice and face models, in which sequences a given person appears, each face being associated with an unique voice. However, in some applications, this audio/video association is not available. For example, in our case, we do not have any prior model: models are computed on the fly, when the persons appear. That is why we present a framework for audio/video association in order to compute automatically these association models.
.png)
Overview
From audio speaker segmentation and a video costume segmentation made on an audiovisual document, we make an automatic association between each voice and the images containing the corresponding visual person. This association can be used as a pre processing step for existing applications like person identification systems. The first step consists in fusing, without any a priori knowledge, the two indexes produced by audio and video segmentations, in order to make the information brought by each of them more robust. Our goal is not to improve descriptor or segmentation method qualities but this fusion step permits to reduce audio and/or video over segmentations in order to make the best association between voices and appearing persons. The speaker segmentation we use is based on a method for speaker diarization. This method operates without any a priori knowledge about speakers and is consists in partitioning the audio stream into segments where each speech segment must be as long as possible and must contain ideally the speech of only one speaker, followed by a clustering step that consists in giving the same label to segments uttered by the same speaker. Ideally, each cluster corresponds to only one speaker and vice versa. The second segmentation is related to a face-based costume detection whose first step is a face detection, so as to detect the different possible characters who are present in the current frame, and their approximate position and scale. Then, the costume of each character is extracted from the image according to the location and the scale of his face. Each segmentation provides an index (audio or video) in the form of a list of 3-tuples, each 3-tuples being composed of <begin segment, end segment, label>. We propose also a common scale for audio and video indexes so that we can then compare and fuse them.
Index intersection
First, we compute a matrix which represents the intersection between audio and video indexes. We use the following notations:
- na is the number of different voices in the audio index,
- nv is the number of different visual persons in the video index,
- {Ai}i=1…na is the set of voices of all persons,
- {Vj}j=1…nv is the set of visual features of all persons.
To compute this intersection matrix, we go through the two indexes, frame by frame. For each frame, if the voice Ai is heard and the visual person Vj is present, the number of occurrences mij of the pair (Ai, Vj ) is incremented. Then, we obtain the following matrix:
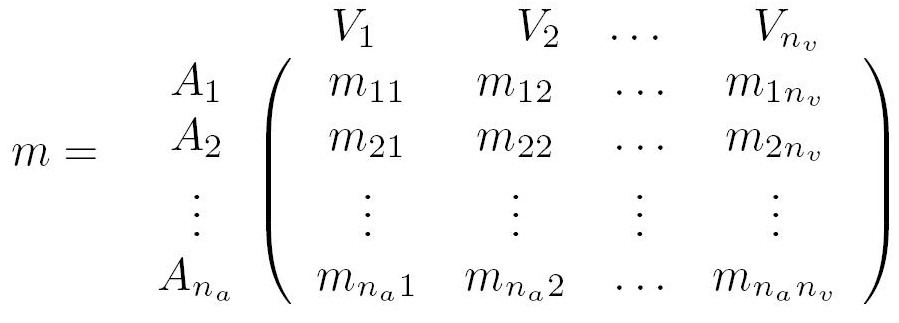
In this matrix, the value mij means that in all the frames where the voice Ai is heard, the visual person Vj appears mij times. Conversely, in all the frames where the person Vj is present, the voice Ai is heard mij times. An intuitive idea would be to sort this matrix by rows (or by columns). However, this solution is often wrong, because it makes the assumption that while a voice is heard, its corresponding visual feature is the most present in the frames (sorting by rows). Sorting by columns would mean that for each visual feature its corresponding voice is the most heard while the feature appears. So, we propose to read m both by rows and by columns, and to keep the most significant information. To carry out this fusion, we compute two new matrices, ma and mv, where the frame numbers are replaced with percentage by rows and by columns:
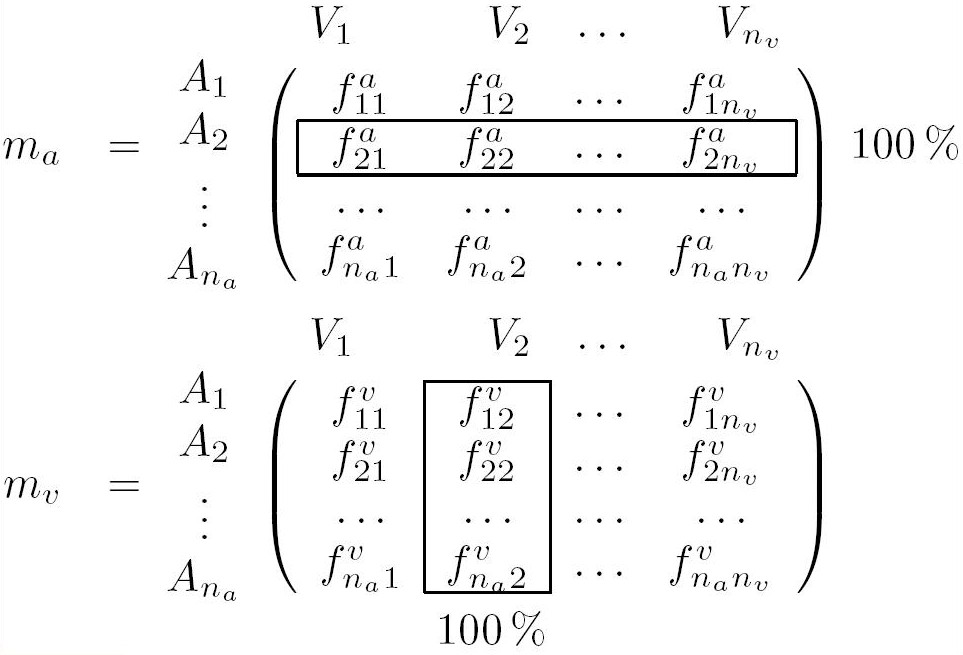
Matrix ma gives the probability density of each voice Ai , whereas mv gives the one of each visual feature Vj . From these matrices, we define the fusion matrix F, by computing, for each pair (i, j), a fusion between faij and fvij with a fusion operator like maximum, mean or product. If we note C(Ai , Vj ) the fusion coefficient between Ai and Vj , expression of matrix F is given by:
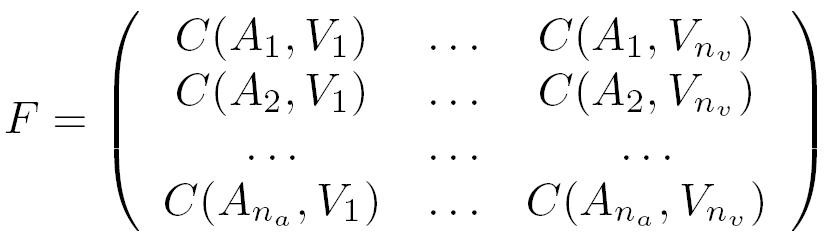
This matrix F can be directly used to realize the association. When the number of voices and visual features is the same (na = nv), it is read equally by rows or by columns. For instance, for each row i, we search the column j which provides the maximum value: then the voice Ai is automatically associated to the visual feature Vj.
Results
To estimate the accuracy of our method, we made several tests on a french TV game. This french TV game is not a representative test-set but it provides a good corpus for a preliminary study. This game lasts thirty one minutes, which provides 46 464 frames. The format of this video is MPEG-1, with a frame size of 352 × 288. In order to obtain the ground truth we manually indexed this game by describing, in each frame, all the viewed characters. This annotation was made in both audio and video streams. For both channels, we used the same labels to identify the characters. If both audio and video streams are correctly segmented, this automatic association yields excellent results. When the two streams are over segmented, our system permits to detect the main persons in term of duration of appearance. Finally, we obtained ten characters that visually appear in the video, and eight voices. This difference is due to two characters who never speak, thus they theoretically cannot be associated to any voice.

Fig. 1. Automatic fusion of the costumes which correspond to the same character.
The label “character 6” is associated with the noise. That is why the audience members have the same label.
Contributors
- Gaël Jaffré
- Elie El Khoury
- Philippe Joly (contact)
- Julien Pinquier (contact)
- Christine Senac (contact)
Publications
Elie El Khoury, Gaël Jaffré, Julien Pinquier, Christine Senac. Association of Audio and Video Segmentations for Automatic Person Indexing. Dans : International Workshop on Content-Based Multimedia Indexing (poster session) (CBMI 2007), Bordeaux, France, 25/06/07-27/06/07, IEEE, p. 287-294, 2007.