
Jingle Detection
Context
A jingle is a short and repetitive melody, sometimes accompanied by speech, used to announce a change in the audio flux. We are interested in detecting and identifing them because we want to use them to structure and describe audio documents.
Our algorithm is based on comparing a given jingle to the audio flux. This comparison is made by computing a spectral distance between the jingle and the document. A first step gives the temporal positions of the jingles and some candidate(s) for each occurrence. In the second step, we select the correct candidate.
Overview
Our method is based on the computing of a spectral distance between “jingle references” and the audio document”. Therefore, we have to dispose of one occurrence of each jingle we are looking for, which compose a “reference set”.
The method is composed of two step: firstly, the detection of the jingles, then their identification.
First step : identification
The spectral distance between a jingle and the document Dj is computed for each jingle j of the reference set. Obviously, if there is an occuence of the jingle at the intant t, there must be a minimum in the distance. However, minima can appear, while there is no occurences of any jingles. In order to avoid false alarms, we define some other rules to validate a minimum as a jingle occurence:
- The minimum must be lower than a threashold λ1, which depends of the distance.
- The minimum must also be “tight” : we estimate the width L of the peak at the heigh H, which depends of the current value h of the minimum. L must be lower than an experiemental threashold to be validated as an occuence. This can be explained by the fact that a jingle does not occure twice at very close instants. So if there is a wide peak, it must come from another sound (music for example) which is spectraly close to the jingle.
An occurrence is detected if there is a tight minimum (see figure 1) in the distance Dj.
.png)
figure 1: Distance between a jingle spectral signature and an audio document. 4 minima are detected, 3 of them are validated using the value L.
Unfortunately, a location may correspond to a minimum of several jingle distances Dj (several distances have minima at very close instants). This is due to the fact that, for the audio consistency of a radio, all the jingles share some characteristics, in order to allow the listener to recognise the radio.
However, the correct jingle is one of the candidates: these minima give us the potential candidates between which we choose the right one.
Second step : detection
The aim of this step is to determine which jingle is the right candidate in the case of close minima in more than one distance Dj.
The solution is very simple: we just have to compare the values of the minima, the correct jingle is the one which has the lowest distance minimum (see figure 2).
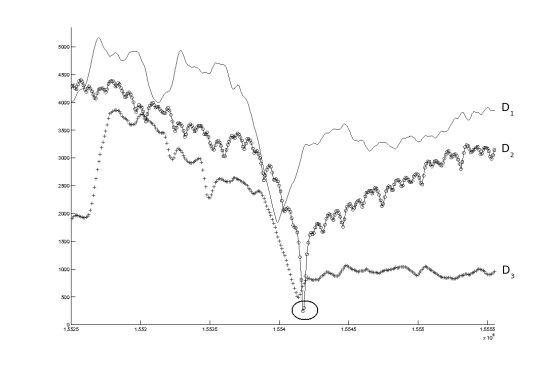
Figure 2: 3 jingles candidates are detected at the same time: 3 minima appear at very close instants, on the distances d1, d2 and d3 corresponding to 3 different jingles. The correct jingle is the one circled.
Evaluation
The evaluation was conducted on 10 hours of a french radio (France Info). This is a news channel, which has a lot of jingles (approximately 30 jingles per hour). These 10 hours were taken on 5 consecutive days, between noon and 1 p.m., and between 5 p.m. and 6 p.m. One of these 10 hours was used to select one occurrence of each jingle, which gave us 21 jingles in the reference set. The tests were conducted on the other 9 hours of the corpus.
On these 9 hours, there were 196 occurrences to detect. With our method, we could detect 195 (99.5%) of them, for only 13 insertions (6.6%). The insertions were mostly due to musical extract that were present in the flux.
To evaluate the performance of the identification step, we must consider the 21 jingles present in the reference set. 20 of them were always correctly identified. The only one which is not recognised is almost always taken for the same other one. Listening these two jingles, we realise that they are very similar : they have almost the same duration, and differ only for a few notes. This similarity is due to the fact that their meanings are close, as they both introduce news flashes.
Contributors
Projects
EPAC Project (ANR 2006 Masse de données – Connaissances Ambiantes): Mass Audio Documents Exploration for Extraction and Processing of conversational speech.
Main publications
Julien Pinquier, Régine André-Obrecht. Jingle detection and identification in audio documents. In : Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP’2004), Montréal, Canada, 17/05/2004-21/05/2004, Vol. IV, IEEE, p. 329-332, may 2004.