
Speaker Diarization
Context
In the context of audio document indexing and retrieval, speaker diarization is the process which detects speakers turns and regroups those uttered by the same speaker. It is generally based on a first step of segmentation (often preceded by a speech detection phase) that consists in partitioning the regions of speech into segments (each segment must be as long as possible and must contain ideally the speech of only one speaker), followed by a clustering step that consists in giving the same label to segments uttered by the same speaker. Ideally, each cluster corresponds to only one speaker and vice versa. Most of the systems operate without specific a priori knowledge of speakers or their number in the document.But, in spite of tremendous progress, they generally need specific tuning and parameters training.
On the contrary, we present a new approach we tried to make the more robust and portable.

Overview
The audio documents we process differ in the quality of recordings (bandwidth, microphones, noise…), the number of speakers and the structure of the speech (duration, sequencing of speaker turns). But they particularly contain multiple audio sources, possibly overlapped, such as music segments, jingles, commercials, noises, different speakers… In this context, a preliminary speech detection step (that separates the regions of speech and the regions containing music, silence, noise) will necessarily miss some speech regions overlapped with music: these missed detections are then irretrievable. It is why we chose to process the segmentation directly on the raw audio file without any preliminary speech detection.
- For the segmentation phase, we combine the Generalized Likelihood Ratio (GLR) and the Bayesian Information Criterion (BIC) in a way that avoids most of the parameters tuning (comparing to existing methods).
- The clustering consists in collecting all segments corresponding ideally to the same speaker. In our case, segments may contain pure speech or speech overlapped with music or music segments (jingles are accurately separated from adjacent music regions). Our clustering method is based on the work of Tsai and al. [1] which utilizes EVSM with a hierarchical bottom-up clustering. Figure 1 presents the different steps: from all the segments Si a universal Gaussian Mixture Model (GMM) Λ is created. This GMM is then adapted on each segment Si to obtain the GMM Λi. From each Λi, a super-vector Vi is created by concatenating the mean vectors of each gaussian distribution of that Λi. Then, PCA (Principal Component Analysis) is applied to obtain from each vector Vi, a vector Wi with a lower dimension. Then, cosine formula calculates similarity between each two vectors (Wi, Wj).The stopping criterion is based on a threshold comparison: if the cosine is higher than this threshold th1, the two segments are groupe. Our contribution consists in choosing a stronger merging criterion based both on the previous similarity measure and on prosodic information which is not yet exploited by diarization systems. The F0 feature is estimated every 10ms on voiced regions with ESPS signal processing software which utilizes the normalized cross correlation function and dynamic. Then, a difference (called ?F0) between the averages of the F0 values of each couple of segments is calculated. We have to notice that, whatever the software, some pure music segments will be considered erroneously as voiced regions of the signal; but they will never be grouped with speakers segments because of the cosine similarity which separates them. The new merging criterion becomes (as illustrated in Figure 3): the two segments correspond to the same speaker if 1) the similarity (cosine formula) is higher than a threshold th1 and 2) ?F0 is lower than a threshold th2.
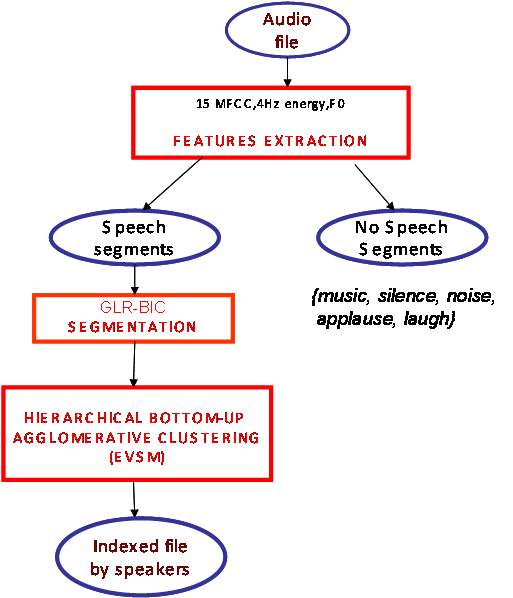
Figure 1 : Overview of the speaker diarization system
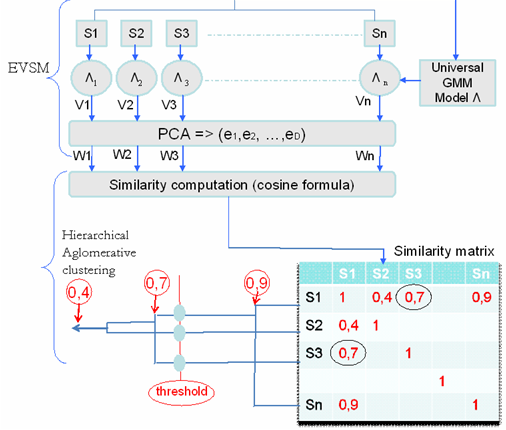
Figure 2. Clustering step: EVSM + Hierarchical agglomerativeclustering
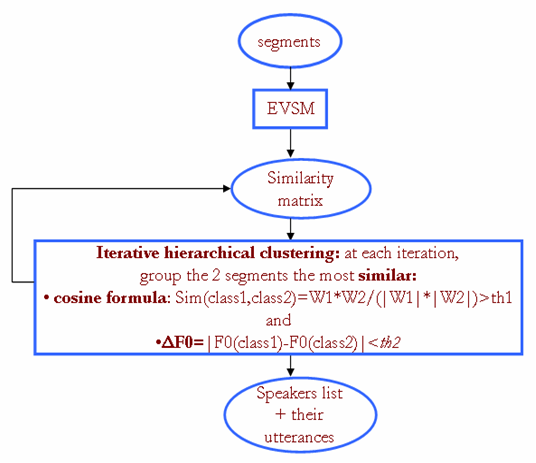
Figure 3. The proposed clustering
Evaluation
Experiments were done on 24 hours of Broadcast News taken from ESTER campaign’s data: we took 4 hours from phase1 for tuning the parameters and we took 20 hours for testing (10 hours from phase1 (different files from tuning files) and the 10 hours of test files of phase2).
To evaluate our method, we used the NIST scoring software (http://nist.gov/speech/tests/rt/rt2005/spring/). We chose 12 MFCC (calculated each 10 ms) for the segmentation step, and 15 MFCC + Energy for the clustering step. In addition, we considered that each segment is modeled by a GMM with 128 Gaussian distributions. Also, we fixed λ to 1, the thresholds th1 to 0.7 and th2 to 40Hz.
Results show that the proposed segmentation “GLR+?BIC” gives an absolute improvement of 12.74% compared to the “?BIC + shifted variable size window” segmentation using the same “EVSM + hierarchical clustering” step. Also, the proposed clustering with prosodic information (EVSM + ?F0 + Hierarchical clustering) method gives additional improvement of 4.81%.
After observation of results, we verified that short speakers turns (>0.6second), different music styles and phone speech are well detected and the corresponding segments are well grouped. Main errors may occur for simultaneous speakers, speakers with music background, and consecutive speakers with the same gender and who are very difficult to distinguish by human ear.
| Segmentation step | ?BIC + shifted variable size window | GLR+?BIC | GLR+?BIC |
| Clustering step | EVSM + Hierarchical clustering | EVSM + Hierarchical clustering | EVSM +?F0 +Hierarchical clustering |
| Missed detection | 3.42% | 0.48% | 0.14% |
| False alarm | 0.98% | 2.46% | 2.4% |
| Speaker error rate | 29.87% | 18.59% | 14.18% |
| Overall DER | 34.27% | 21.53% | 16.72% |
Projects
- EPAC Project (ANR 2006 Masse de données – Connaissances Ambiantes): Mass Audio Documents Exploration for Extraction and Processing of conversational speech
- MUSCLE Project
- A01 Project: Automatic Indexing of speakers in audio-visual sequences using multimodal approach
Contributors
Publications
- Elie El Khoury, Christine Senac, Régine André-Obrecht. Speaker Diarization: Towards a more Robust and Portable System. In: IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2007), Honolulu, Hawaii, USA, 15/04/07-20/04/07, IEEE, p. 489-492, 2007.
- Elie El Khoury, Gaël Jaffré, Julien Pinquier, Christine Senac. Association of Audio and Video Segmentations for Automatic Person Indexing. In: International Workshop on Content-Based Multimedia Indexing (poster session) (CBMI 2007), Bordeaux, France, 25/06/07-27/06/07, IEEE, p. 287-294, 2007.
- Elie El Khoury, Sylvain Meigner, Christine Senac: Projet EPAC: segmentation et regroupement en locuteurs. In : JEP, 2008 (to appear).