
Language identification
Context
The aim of an Automatic Language Identification (ALI) system is to identify the language spoken within a few seconds speech excerpt. The uprising development of communications between humans and between humans and computers renew the interest in such systems. The reactualization of multilingual interactive vocal servers and language characterization in front of audio-visual content indexing are an exemple of the main possible applications. Automatic Language Evaluation consists in telling if an hypothesis language match to the language spoken in the speech file. This form of verification is usually employed in international evaluations.
Overview
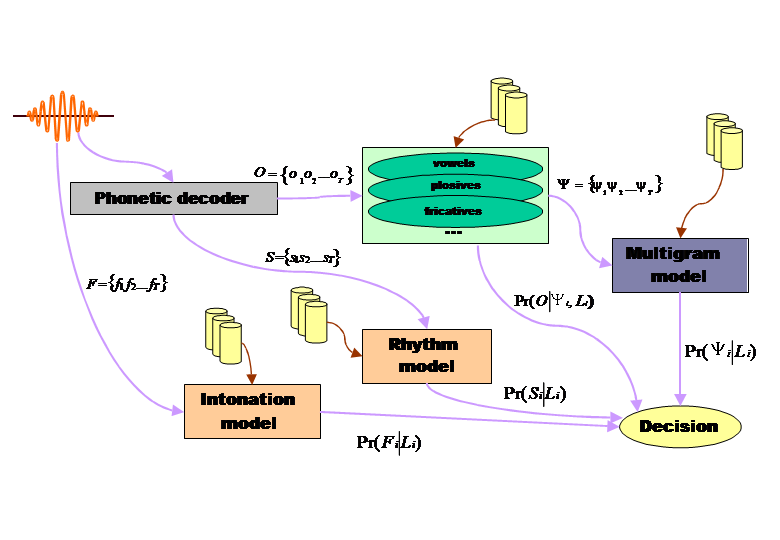
Our aim is to make a complete ALI system, which should use acoustics, phonotactics and prosody, after choosing relevant parameters. This system will compose in three modules:
- An generalized acoustico-phonetic decoding module to take into account the languages diversity in the acoustic space level,
- A language model to model the sound sequences frequencies,
- A prosodic model to model the languages rhythm and intonation.
Acoustico-phonetic module
Most of the actual ALI systems use speech recognition technologies, whether for the pre-processing (RASTA filter, speech activity detection) or for the modeling (female and male model separation, units choice…). For ALI, it is necessary to optimize the phonetic cover of each language.
We propose an approach, the differenciated phonetic modeling, which is based on the following asseses:
- The languages typologies distinguish between vocalic and consonantal systems, and inside of those systems, some consonants can also be represented in different spaces (fricatives, plosives…)
- Those languages typologies can also be used to identify a language (or a family of languages) from its phonological description.
- The most relevant features to characterize a sound can depend on its phonetic class: to describe a plosive in the formant space is inadequate, whereas it is the right space for other sounds.
- When we try to model together homogenous sounds (for exemple vowels), it is easier to take into account some specific constraints (acoustic limits of the acoustic space in this exemple)
These remarks have lead us to consider a differenciated modeling for each phonologic system (vocalic system, fricative consonants system…) redefined regarding to constraints linked to the acoustico-phonetic representation of spontaneous speech (for example coarticulation).
Phonotactic module
The best performances in ALI are obtained with phonotactic modeling. One of the main advantages of those systems is that they can be automatically trained with no labeled data. Our system’s phonotactic module is right behind the acoustico-phonetic decoder: it uses the acoustico-phonetic units given by the differenciated phonetic modeling.
Prosodic module
From an acoustic point of view, prosody indicates the phenomena linked to the time variations of height, intensity, and duration. The height perception is mainly linked to the fundamental frequency (noted F0) which is, at the phonologic level of speech description, the vibration frequency of the vocal strings.The perception of intensity is linked to the sound amplitude and energy, but also partially depends on its duration. The duration perception corresponds to its execution time, its acoustic duration.
On the perceptuel point of view, the time variation of the above parameters defines the utterances melody perception, and their rhythmic and stress perception. The utterance melody is the time evolution of height. The stress is a high level phenomenon, which is defined by the highlighting of a syllable or a more regarding to its neighbors. The rhythm of an utterance is perceived thanks to the sequence of segments durations.
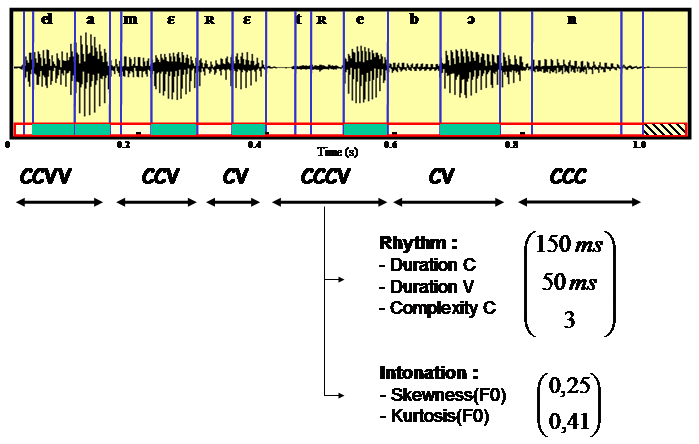
From a prosodic point of view, languages differ in their rhythm and intonation. Our assumption is that rhythm is produced by the periodicity of a pattern that can be syllable, which is a language specific unit. That is why we introduced the notion of “Pseudo-Syllable”, derived from the most frequent syllable structure in the world, the Consonant-Vowel structure. We propose an automatic and language independent rhythm extraction algorithm: using a vowel detection algorithm, rhythmic units matching the Consonant-Vowel structure are segmented. Several parameters are extracted including consonantal and vowel durations, and cluster complexity. Other features related to pitch and intensity are also considered to model the languages tones. Two models describing rhythm and intonation of each language are then learned using Gaussian Mixtures. This basic model can be enhanced with an micro and macro prosody modelling, and produce a more reliable model of the language.
Contributors
- Jérôme Farinas (contact)
- Eduardo Sanchez Soto
- José Anibal Arias
- Régine André-Obrecht (contact)
- François Pellegrino
- Jean-Luc Rouas
Projects
- MISTRAL Project (ANR 2006 Technologies Logicielles): An open source biometric authentification framwork (with LIA, LIG, LIUM, EURECOM, Thales, Calistel)
- EPAC Project (ANR 2006 Masse de Données – Connaissances Ambiantes): Mass Audio Documents Exploration for Extraction and Processing of conversational speech (with LIUM, LIA)
- KLIMT (ITEA 2002-2004): KnowLedge InterMediation Technology (with THALES & co)
- RAIVES (CNRS 2002-2003): Automatic Retrieval of Audio & Speech Informations (with DDL, LORIA)
- European Lid (Emergence 2000) 2000-2003: Language Identification on European languages (with DDL, ISC, UC Berkeley)
- Afro-asiatic Lid (APN SHS-CNRS 2000-2002): Language Identification on Afro-asiatic languages and dialects (with DDL, ISC, UC Berkeley)
- DGA (1996-1998): multilingual discrimination (with ICP, ILPGA, DDL)
Main Publications
- Jean-Luc Rouas, Jérôme Farinas, François Pellegrino, Régine André-Obrecht. Rhythmic unit extraction and modelling for automatic language identification. Dans : Speech Communication, Elsevier, Vol. 47 N. 4, p. 436-456, 2005. Paper Link
- François Pellegrino, Régine André-Obrecht. Automatic language identification: an alternative approach to phonetic modelling. Dans : Signal Processing, Elsevier Science, North Holland, Vol. 80, p. 1231-1244, juillet 2000.
- Jérôme Farinas, Jean-Luc Rouas, François Pellegrino, Régine André-Obrecht. Extraction automatique de paramètres prosodiques pour l’identification automatique des langues. Dans : Traitement du Signal, GRETSI CNRS, Vol. 22, N. 2, p. 81-97, 2005.