Features Extractions
Context
The objective of the feature extraction step is to capture the most relevant and discriminate characteristics of the signal to recognize. Although characters in the same class have some variances due to different spoken styles for different users, there must exist some consistencies. That is why feature extraction is needed and those features extracted are put into a classifier.
The features used in our speech / music classification system are:
- Cepstral coefficients
- Spectral coefficients
- 4 Hz modulation energy
- Entropy modulation
- Number of “stationary” segments
- Segment duration
Overview
Cepstral coefficients
Cepstral coefficients are the coefficients of the fourier transform representation of the log magnitude spectrum (see [Digital Signal Processing, 1974] for more details).
Spectral coefficients
One of the more common techniques of studying a speech signal is via the power spectrum. The power spectrum of a speech signal describes the frequency content of the signal over time (see [Scheirer, 1997] for more details).
4 Hz modulation energy
Speech signal has a characteristic energy modulation peak around the 4 Hz syllabic rate. In order to model this property, the classical procedure is applied: the signal is segmented in 16 ms frames. Mel Frequency Spectrum Coefficients are extracted and energy is computed in 40 perceptual channels. This energy is then filtered with a FIR band pass filter, centered on 4 Hz. Energy is summed for all channels, and normalized by the mean energy on the frame. The modulation is obtained by computing the variance of filtered energy in dB on one second of signal. Speech (Figure 1a) carries more modulation energy than music (Figure 1b).
| Figure 1a: 4 Hz energy modulation for speech | Figure 1b: 4 Hz energy modulation for music |
Entropy modulation
Music appears to be more ordered than speech considering observations of both signals and spectrograms. To measure this disorder, we evaluate a feature based on signal entropy:
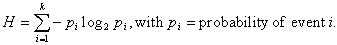
The signal is segmented in 16 ms frames, the entropy is computed on every frame. This measure is used to compute the entropy modulation on one second of signal. Entropy modulation is higher for speech (Figure 2a) than for music (Figure 2b) with signals of the previous paragraph.
| Figure 2a: entropy modulation for speech | Figure 2b: entropy modulation for music |
Number of segments
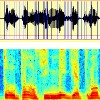
The duration feature is the consequence of the application of the segmentation algorithm. The speech signal is composed of alternate periods of transient and steady parts (steady parts are mainly vowels). Meanwhile, music is more constant, that is to say the number of changes (segments) will be greater for speech (Figure 3a) than for music (Figure 3b). To estimate this feature, we compute the number of segments on one second of signal.
| Figure 3a: segmentation and spectrogram on about 1 second of speech | Figure 3b: segmentation and spectrogram on about 1 second of music |
Segment duration
The segments (see segmentation algorithm ) are generally longer for music (Figure 3b) than for speech (Figure 3a). We have decided to model the segment duration by a Gaussian Inverse law (Wald law).
The probability density function (pdf) is given by:
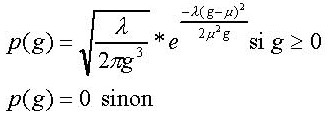
Contributors
Régine André-Obrecht (contact)
Jean-Luc Rouas
Projects
FERIA
Main Publications
Julien Pinquier, Jean-Luc Rouas, Régine André-Obrecht. A Fusion Study in Speech/Music Classification. In : International Conference on Acoustics, Speech and Signal Processing (ICASSP’2003), Hong Kong, China, 06/04/03-10/04/03, Vol. II, IEEE, p. 17-20, avril 2003.
Julien Pinquier. Indexation sonore : recherche de composantes primaires pour une structuration audiovisuelle. Thèse de doctorat, Université Paul Sabatier, décembre 2004.
References
Oppenheim A. and Schafer R., Digital Signal Processing, Upper Saddle River, NJ: Prentice-Hall, 1974.
Scheirer E. and Slaney M., Construction and Evaluation of a Robust Multifeature Speech/Music Discriminator, ICASSP’97, Munich, 1997.