
Deformable / non-deformable object analysis
Context
The recent tendency in multimedia domain is the semantic video understanding by automatic video analyzing. For that purpose, it is very important to know and study the video contents; i.e. background, actions, objects and their movements to better understand their meaning. Accordingly, object properties are very important issues. One important property which can significantly facilitate the understanding of object movements is the object deformability; which means knowing if the object is deformable or non-deformable. Naturally, the object deformability property is important by itself. However the inference of deformability is difficult without additional information about the object’s shape or the environment. We propose a new fully automated way to differ rigid/non-rigid motion and infer deformable/non-deformable object. Our method deals with any kind of videos (video surveillance, sport, news…) whether they are grayscale or colored. However, we consider only the videos taken by static cameras and where there is only one object in the scene. Without having any priori information about the environment, the shape of the object and its displacement, and with no pre-assumptions, our approach can detect using a fully automated method any kind of moving object in the scene and estimate motion vectors field. It studies the movements, differentiates rigid from non-rigid motions taking into consideration that a non-rigid object can temporary acts as rigid (have a rigid motion), and benefits from the temporal consistency to infer whether the moving object is deformable or non-deformable.
Overview
The proposed approach follows five steps:
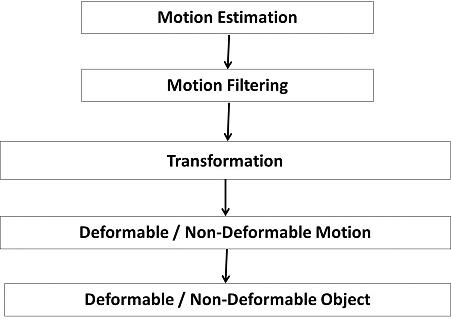
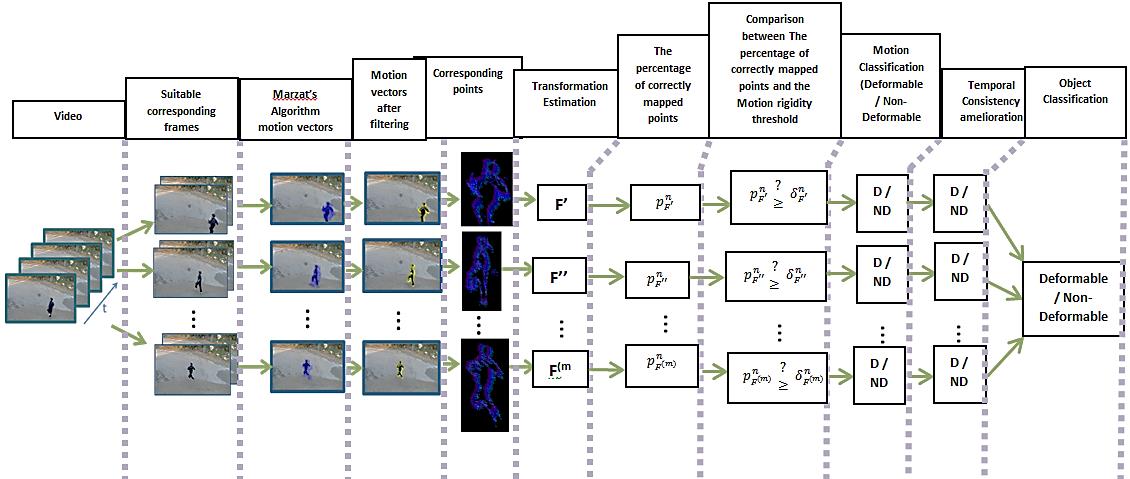
The suitable changeable spaces between frames were found, indicating the suitable acceptable length range of motions. Motions were estimated using Marzat’s optical flow algorithm, so the output of this step will be motion vectors belonging to the moving object, false vectors detected outside the moving object, false estimated vectors inside the moving object, and unusable motion vectors. Then, motion vectors were filtered using 3 filters (small vectors, uniformity, and texture filters). This will delete false, miss-estimated, and unusable motion vectors. Only most reliable motion vectors belonging to the moving object remain, pointing out the corresponding points between the two image frames. Transformations (fundamental and homograghy) that can represent the correct mapping between the two sets of corresponding points were searched, taking into consideration the normalization level of the Average Length of Motions Field, the type of measurement distances, and the Mapping acceptable error. The Fundamental matrix F was estimated using the Normalized 8-Point Algorithm (N8PA) and the Homography matrix H using the Normalized Direct Linear Transform (NDLT). Percentages of correctly mapped points corresponding to each estimated transformation were calculated. A new type of graph was presented leading to better calculation of ultimate motion rigidity thresholds, which can differ rigid from non-rigid motion (temporary motion). The consistency of motion classification was studied and errors were corrected using temporary information, which lead to finally infer deformable from non-deformable object. A wide variety of video contents was used for experiments, different types of scenes, objects, and motion.
Applications
This algorithm classifies any object in a video as deformable or non-deformable. In addition to that, it differentiates each momentary motion of this moving object as rigid or non-rigid motion.
For semantic video understanding, object deformability is an important property that helps analyzing the object, its movements, and better understanding their meanings. Classifying objects as deformable or non-deformable can assist qualifying the actioner and the actionee; it also gives the main clues to well understand the action. Moreover, it would allow a tracking system to rely more on appropriate measurements and improve performance.
Contributors
(Contribution Franco-Libanaise)
- Wael Youssef,
- Siba Haïdar
- Philippe Joly (contact)