
Audiovisual signature
Context
The neOCampus operation, started in June 2013, brings together 11 laboratories of the University Paul Sabatier, Toulouse: CESBIO, CIRIMAT, ECOLAB, IRIT, LAAS, LAPLACE, LCC, LERASS, LMDC, PHASE and LA, aiming to create a connected, innovative, sustainable and self-adaptative campus to improve everyday comfort, decrease the ecological footprint and reduce operating costs. Since the operation monitors unsupervised users (students, teachers, staff), an upstream human activity detection is required.
This detection task can be inferred by audiovisually tracking the users of the campus. Therefore, we set up a sparse network of heterogeneous sensors (cameras and microphones) on the buildings. The tracking of a person can be carried by learning its audiovisual signature, requiring:
- Audio and Visual Signatures Characterizations
- Audio and Visual Person Localizations
- Audio and Visual Signatures Fusion
Overview
The whole architecture of our system is shown in the figure below.
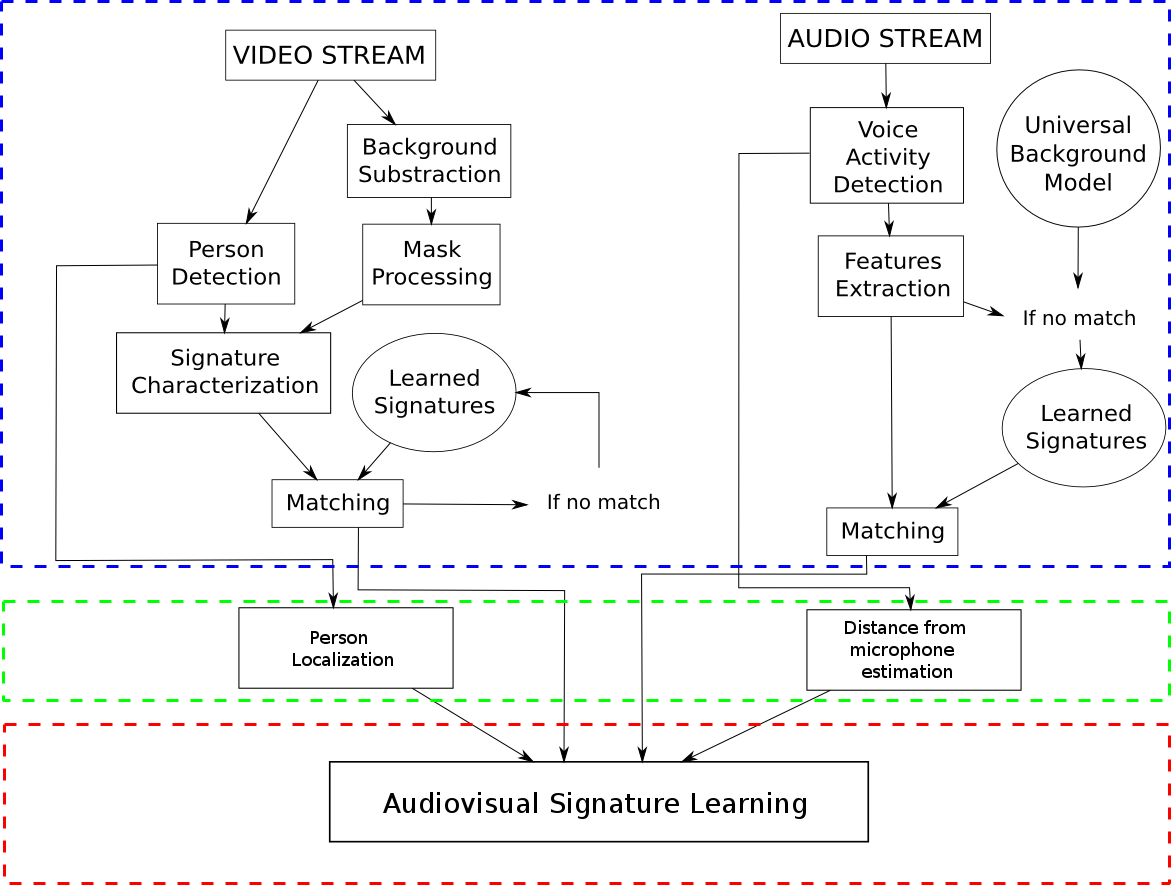
Synoptic of our multi-sensor platform
Audio and Visual Signatures Characterizations
This section is shown in the sub-synoptic in blue in the architecture figure. We first characterize the audio and visual signatures separately.
Audio Signature
| We build the audio signature of a person using the following procedure:Voice Activity DetectionAudio Features ExtractionModeling and Matching |
Voice Avtivity Detection
Voice activity activity detection, and more precisely speech detection is performed using 4Hz modulation energy extraction, presented here.
We exploit the particularity that speech has a peak at 4Hz in its modulation spectrum, corresponding to the common syllabic rate. We then segment the audio stream into one-second frames (whith overlapping) and filter it by a [2Hz-16Hz] bandpass. The segments with an energy modulation higher than a trained threshold are classified as speech, and the others as noise.
Audio Features Extraction
This step consists in choosing the most discriminative features, extracted from the speech frames, to best model each speaker. We selected a vector of features based on a linear filter-bank of 19 filters derived cepstra, using perceptive MEL scale. Each vector is composed of 50 coefficients, namely 19 static, 19 delta and 11 delta-delta and the delta energy.
Modeling and Matching
A Gaussian Mixture Model (GMM) is then fed with the previously described features and the audio signature of the detected speaker is represented by the parameters of this distribution (the means and covariance matrices of each gaussian component). Instead of inferring them directly, we perform a Maximum A Posteriori (MAP) adaptation from a Universal Background Model (UBM) to lower the required volume of training data.
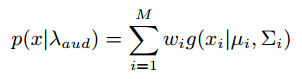
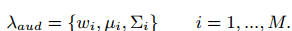
with : the parameters of all gaussian components. Considering a feature vector y of an observed speech segment Y, the matching step is carried out by computing a similarity score as the loglikelihood ratio (LLR) between the hypothesis of Y spoken by our trained speaker vs. Y spoken by another one, closer to the UBM:
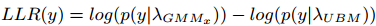
Visual Signature
| We build the visual signature of a person using a similar procedure:Visual Person DetectionVideo Features ExtractionMatching |
Visual Person Detection
Numerous algorithms have been developed to carry out the task of detecting humans in visual frames. One of the most popular approach is to use Histograms of Oriented Gradients (HOG). It consists in characterizing the person’s shape by the distribution of local intensity gradients or edge directions. A linear SVM is then fed for person/non-person classification (see [Dalal, 2005] for more details).
Video Features Extraction
As for audio, a well discriminative set of visual features is required to perform reidentification. The majority of them follows a part-based model. In our case, the Symmetry-Driven Accumulation of Local Features (SDALF, see [Farenzena, 2010] for more details), the silhouette is subdivided into head, torso and legs by looking for horizontal axis separating regions with strongly different appearance and similar area. The SDALF descriptor achieves excellent state-of-the-art performances by its robustness against very low resolution, occlusions and pose, viewpoint and illumination changes. It is computed as a combination of 3 features extracted from the body parts, but we only uses on of them, HSV histograms, as it performs satisfyingly and for a limited computational cost: HSV is chosen over RGB for its robustness to illumination changes. An upstream background substraction, carried out by an online GMM training of the background is used for selecting the pixels corresponding to the person only.
Modeling and Matching
To compute a storable and transportable visual signature, a k-means clustering is applied on a set of descriptors of a single person, then the k closest to each centroid are concatenated to form the signature, containing great variations of views and poses:
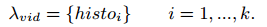
For the matching step, histograms similarities are computed by the Bhattacharyya distance.
Audio and Visual Person Localizations
Audio Localization
In single-microphone or distant-microphones contexts, binaural cues for localization such as the Interaural Level Difference (ILD) or the Interaural Time Difference (ITD) are impossible to use but acoustic features for close distance-to-listener estimation can be extracted. Distance appears to be correlated to the Direct-to-Reverberant energy Ratio (DRR), that we estimate by the Speech to Reverberation Modulation energy Ratio (SRMR, see [Falk, 2010] for more details), as show on the figure below:
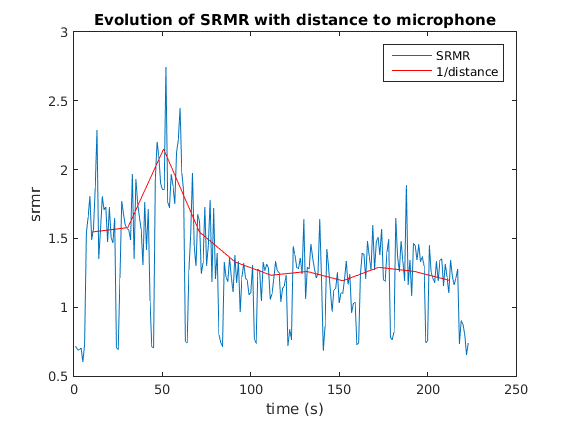
SRMR of 11 iterations of a speech segment from different distances and a frame length of 1s
The modulation spectrum of a dry speech signal (spectrum of its temporal envelope) has components distributed around 2-16Hz, with peaks at 4Hz, the common syllabic rate. Adding reverberation whitens the modulation spectrum and components in higher modulation frequency bands appear. We first filter the input speech signal by a 23-channel gammatone filter bank, then SRMR is defined as the ratio between the energy in low modulation frequency bands and the energy in high modulation frequency bands:
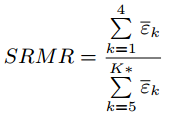
Video Localization
Unlike audio percepts, the positions on the ground plane of the visual detections can be easily inferred from a camera view by calibrating beforehand the ground plane relatively to the camera.
Audio and Visual Signatures Fusion
Audiovisual fusion issue is tackled as a search of both modality salient areas at each instant t. The room is equipped with several cameras C and microphones M in a way that a subset of microphones {Mk} is in the field of view of at least one camera. We introduce two confidence indices, audio (ACI) and video (VCI), representing the likelihood for the detected person to be in the salient zone around a microphone. The ACI will be defined as the SRMR in the microphone Mk, and the VCI the euclidean distance to this microphone. Our joint measure for audiovisual saliency map is then defined as the following AudioVisual Confidence Index:
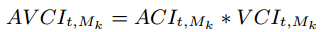
The audiovisual fusion zone is delimited by AVCI values greater than a predefined threshold th. To tune this value, a gaussian Kernel SVM is fed with AVCI values of the training dataset.
Media
Contributors
François-Xavier Decroix(contact)
Main Publications
François-Xavier Decroix, Julien Pinquier, Isabelle Ferrané, Frédéric Lerasle. Online Audiovisual Signature Training for Person Re-identification (regular paper). In : International Conference on Distributed Smart Camera (ICDSC 2016), Paris, 12/09/2016-15/09/2016, ACM, p. 62-68, septembre 2016.
François-Xavier Decroix, Frédéric Lerasle, Julien Pinquier, Isabelle Ferrané. Apprentissage en ligne d’une signature audiovisuelle pour la ré-identification de personne (regular paper). In : RFIA, workshop, Clermont-Ferrand, 27/06/2016-01/07/2016
References
N. Dalal and B. Triggs. Histograms of oriented gradients for human detection. In Computer Vision and Pattern Recognition, 2005. CVPR 2005. IEEE , volume 1, pages 886–893 vol. 1, June 2005.
M. Farenzena, L. Bazzani, A. Perina, V. Murino, and M. Cristani. Person re-identification by symmetry-driven accumulation of local features. In Computer Vision and Pattern Recognition (CVPR), 2010 IEEE, pages 2360–2367, June 2010.
T. Falk, C. Zheng, and W.-Y. Chan. A non-intrusive quality and intelligibility measure of reverberant and dereverberated speech. In : Audio, Speech, and Language Processing, IEEE Transactions on, 18(7):1766–1774, Sept 2010.