
Singing Voice Detection
Context
This research takes place in a context of audio indexing. After some work on the detection of speech and music, the problem of the position of singing appears. Actually, it is music produced by human voice. In our Speech/Music system, it is classifed mainly in the music category, but it was sometimes taken for speech. The purpose of this work is to add a third category to the original classifier.
System Overview
Our system is based on the analysis of a very discriminative descriptor: the vibrato. However this parameters is only computable for solo voices or instruments. In order to be able to use it in the case of polyphonies, we extend this concept, with the help of a new pseudo-temporal segmentation.
Note that, as we proposed in 2009 [Lachambre et al.], a monophony / polyphony distinction can be added as a preprocessing.
Definition and properties of the vibrato
The vibrato is a sinusoidal oscillation of the fundamental frequency (see figure 1). It is often present in music, especially for instruments such as violins, winds, or human singing voice. In the case of instruments, the vibrato is most often produced intentionnaly by the musician. The particularity of the human vibrato (named vibrato in the following article), is that
- it is produced inconsiously,
- it is always present, excepted for professionnal who work to reduce it,
- it frequency is the same for every people in the world: 4-8 Hz.
.png)
.png)
Figure 1: Fundamental frequency for two extracts of 2s – Left: speech, no vibrato – Right: Singing voice, presence of vibrato
The presence of vibrato is confirmed if there is a peak (between 4 and 8 Hz) in the Fourier Transform of the fundamental frequency.
The pseudo-temporal segmentation
We note that the detection of the vibrato implies the capacity to extract the fundamental frequency. In the case of a polyphonie, it would be necessary to extract the fundamental frequency of each instrument/singer, which is not possible at present.
The idea we worked on is that, if there is vibrato on the fundamental frequency, there should also be vibrato on its harmonics. It was so necessary to extract the harmonics, which is done with the sinusoidal segmentation. Then, we had to find temporal segments, on which we would analyse the harmonics.
The extraction of harmonics: the sinusoidal segmentation
The sinusoidal segmentation was firstly developped by [Toru et al.].It realises an automatic frequency tracking. A sinusoidal segment is then defined by 4 parameters: its begining and end, a frequency vector and a power vector.
To compute the sinusoidal segmentation, the algorithm is the following one:
- Compute the spectrogram, every 10ms with a 20ms Hamming window (figure 2),
- convert the frequency in cent (100 cent = 1/2 tone),
- detect the maxima of the spectrogram: their frequency fi,t and their log power pi,t,
- compute the distances between these maxima:
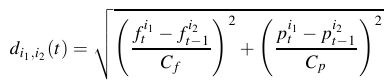
Two points (t, fi1,t) and (t+1,fi1,t+1) belong to the same segment if di1,i2(t) < dth. Cf, Cp and dth are determined experimentaly: Cf = 100 (1/2 tone), Cp = 3 (power divided by 2) and dth = 5. This give us the sinusoidal segments shown on figure 3.
| Figure 2: Spectrogram of an extract of 23s of singing voice | Figure 3: Sinusoidal segmentation of the same extract. Each ligne is a segment |
The temporal boundaries: the pseudo-temporal segmentation
Having the sinusoidal segmentation, our first idea was to analyse each sinusoidal segment, in order to determine if it has vibrato or not. However, the segments are not synchronized, so we need to find a temporal segmentation, which will allow us to analyse the sinusoidal segments.
This new segmentation, the pseudo-temporal segmentation, is based on the fact that, during an harmonic sound (typically a note), the fundamental frequency and its harmonics, each one represented by a sinusoidal segment, begin and end at the same time. Therefore, we analyse the temporal correlations between the beginnings and the ends of the sinusoidal segments:
- compute the sinusoidal segments,
- find all the temporal extremities of the segments, but distinguish the begginnings from the ends,
- place a limit at instant t if there is at least 2 extremities at t, AND 3 begginnings or 3 ends between t and t+1.
A pseudo-temporal segment is then defined by two successive limits (see figure 4).
.png)
Figure 4: Pseudo-temporal segmentation of the same vocal extract. The vertical lines are the limits of the pseudo-temporal segments
The extended vibrato
With the tools presented above, we can extend the notion of vibrato to any type of sounds, mono- or polyphonic. Our new parameter, vibr, represents, in a pseudo-temporal segment, the proportion of sinusoidal segments which have vibrato. The sinusoidal segments from singing will have vibrato, while the others (speech, noise, musical instruments…) won’t. So the value of vibr will be higher in presence of singing.
vibr is computed only for the long pseudo-temporal segments (the short segments are attributed the value 0):
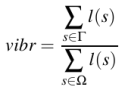
with: l(s) the length of the segment s, Γ the long (> 50ms) sinusoidal segments with vibrato and Ω all the long sinusoidal segments.
The presence of singing voice is given by the following test: Singing = vibr > 0.8.
Contributors
Main publications
Hélène Lachambre, Régine André-Obrecht, Julien Pinquier. Singing Voice Characterization in Monophonic and Polyphonic Contexts. In : Eusipco, Glasgow, Scotland, 2009.
Hélène Lachambre, Régine André-Obrecht, Julien Pinquier. Singing Voice Characterization for Audio Indexing. In : European Signal and Image Processing Conference (EUSIPCO 2007), Poznan, Poland, 03/09/2007-07/09/2007, Polish Society for Theoretical and Applied Electrical Engineering (PTETiS), 2007.
Hélène Lachambre, Régine André-Obrecht, Julien Pinquier. Caractérisation de la voix chantée dans un contexte d’indexation audio. In : Groupe de Recherche et d’Etudes du Traitement du Signal et des Images (GRETSI 2007), Troyes, 11/09/2007-14/09/2007, GRETSI CNRS, 2007. (In french)
References
[Toru et al.] Toru Taniguchi et al. Discrimination of Speech, Musical Instruments and Singing Voices using the Temporal Patterns of Sinusoidal Segments in Audio Signals. In : Interspeech – European Conference on Speech, Communication and Technology, 2005