High Level Feature Extraction
Context
Most of the existing video-search engines rely on context and textual metadata such as the title of the video, tags and comments written by users, etc. In other words, no attempt at understanding the actual content of the video is performed. Content-based audiovisual analysis aims at bridging this so-called semantic gap.
Overview
Our approach to this problem aims at being as generic, modular and automatic as possible:
- Automatic — taking advantage of (and hopefully designing new) data-mining techniques.
- Modular — when a new content descriptor is available, no system re-design should be necessary — it should just acknowledge its availability and make a (smart) use of it.
- Generic — the ideal system would adapt to different type of content (TV shows, news broadcast, movies or user-generated personal movies).
High-level feature extraction is one of those tasks where such an approach would be very helpful. As defined in the TRECVid evaluation campaign organized by NIST, given a large set of videos and associated shot boundaries, the objective is to automatically output a list of shots that contain a pre-defined list of semantic concepts (as varied as chair, cityscape and person singing…).
Support vector machine using unbalanced data
A collaborative annotation effort allowed to annotate the videos of the whole development set with the 20 semantic concepts — thus opening the door to the use of automatic machine-learning techniques.
However, one main problem in this type of problem is the unbalanced nature of the available training dataset: there are much more negative samples (not containing the concept) than positive ones. Support vector machines, for instance, may be disturbed by this issue.
The figures below show one attempt to automatically select a good sub-set of the original training set to achieve better classification performance.
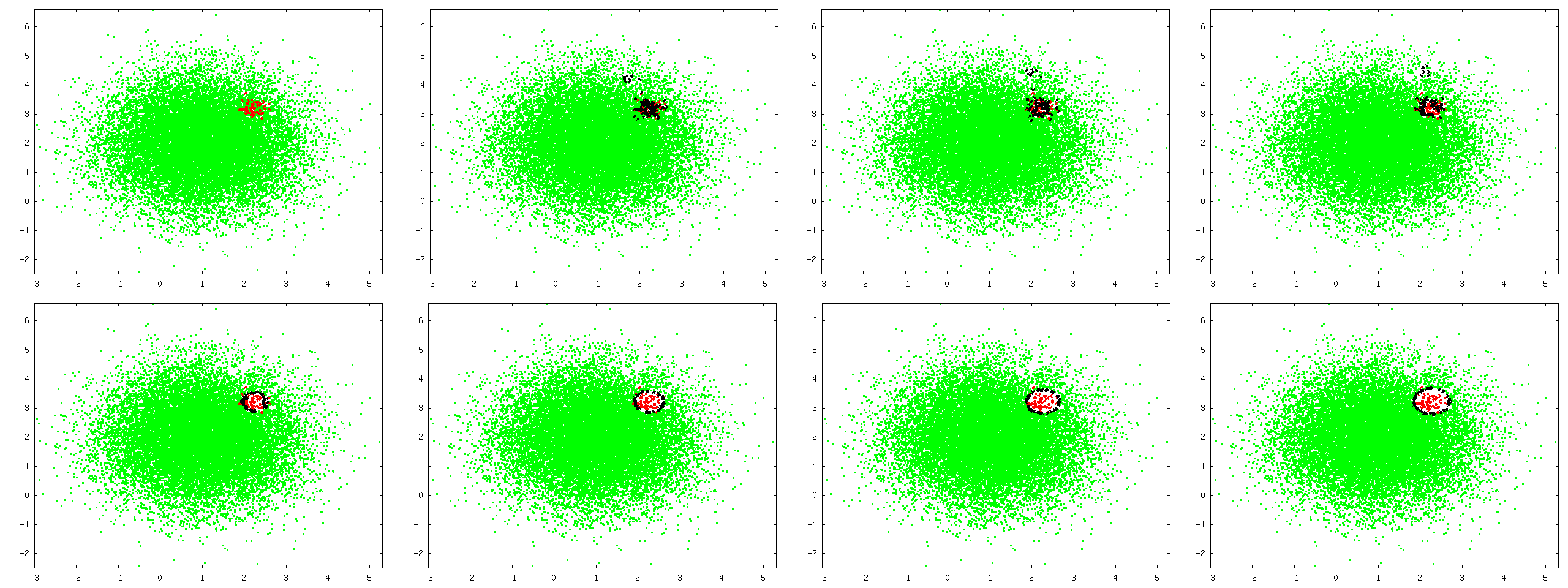
The idea, here, is to iteratively remove support vectors (black) from the dominant class from the training set so that the boundary between positive (red) and negative (green) samples is not too close to the positive samples.
Fusion of multiple descriptors
In the framework of TRECVid 2009 High Level Feature Extraction task, several descriptors, both audio and visual, were extracted, processed and then fused in order to obtain improved performance over mono-modal systems.
A (not-so-exhaustive) list of descriptors include:
- Visual descriptors: SIFT and color local descriptors with “bag-of-words” approach, face detection
- Speech descriptors: MFCC (mel-frequency cepstral coefficients), voicing percentage, 4Hz modulation, …
- Music descriptors: YIN, vibrato, …
- Others audio descriptors: zero-crossing rate, audio energy, spectral statistics
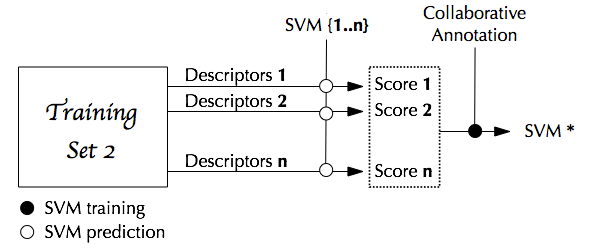
As shown in figures below, each descriptor is used to train one SVM which is further used to output a probability of being part of the positive class (i.e. of containing the semantic concept).

These probabilities are then concatenated into one global vector on which another final SVM* is trained.
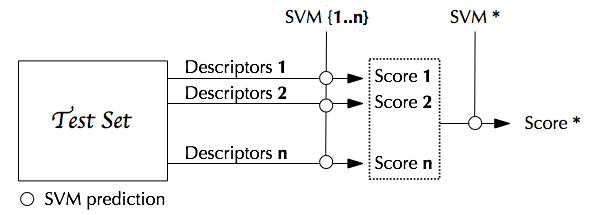
In practice, when a new video is available for semantic concept detection, all descriptors are extracted, mono-descriptors SVM are applied, scores are concatenated and the final score is given by the SVM* classifier.
Main Publications
- Enrique Argones Rúa, Hervé Bredin, Carmen Garcia Mateo, Gérard Chollet, Daniel González Jiménez. Audio-visual speech asynchrony detection using co-inertia analysis and coupled hidden markov models. Dans : Pattern Analysis and Applications Journal, Springer-Verlag, Vol. 12 N. 3, p. 271-284, 2009.
Accès : http://dx.doi.org/10.1007/s10044-008-0121-2 - Gérard Chollet, Rémi Landais, Thomas Hueber, Hervé Bredin, Chafic Mokbel, Patrick Perrot, Leila Zouari. Some Experiments in Audio-Visual Speech Processing. Dans : Advances in Nonlinear Speech Processing. Mohamed Chetouani (Eds.), Springer-Verlag, p. 28-56, Vol. 4885/2007, LNCS, 2007.
- Bouchra Abboud, Hervé Bredin, Guido Aversano , Gérard Chollet. Audio-visual Identity Verification: An Introductory Overview. Dans : Progress in Nonlinear Speech Processing. Yannis Stylianou, Marcos Faundez-Zanuy, Anna Eposito (Eds.), Springer-Verlag, p. 118-134, Vol. 4391/2007, LNCS, 2007.
Contributors