Reading mistakes detection in children’s speech
Context
An alarming observation has been made in several countries: 1 student out of 5 in France and 1 out of 4 in the USA enter middle school with difficulties for reading, compromising their whole schooling. Two major causes of this problem are the heterogeneity of student’s abilities and the growing number of students per classroom, which keeps the teachers from adapting their teaching to each child.
Speech recognition could provide strong and efficient tools to help children practice reading aloud, but current performance of speech recognition for children is below that of the state-of-the-art for adult speech. Young child speech is particularly difficult to recognise, and substantial corpora are missing to train acoustic models. Furthermore, for children learning to read, speech recognition models need to cope with slow reading rate, disfluencies, and classroom-typical babble noise.
Overview
The objective of this research work is to improve automatic speech recognition techniques for the specific population of 5-7-year-old children learning to read, in order to create a tool for automatically assessing a student’s reading level and help diagnose recurrent difficulties.
Challenges
Our application rises many challenges:
- Current performance of speech recognition for children is below that of the state-of-the-art for adult speech, due to phonological and morphological differences
- Quantity of child speech data is highly limited, especially in French
- Educational constraints need to be taken into account
- The application is designed to be used in a classroom, resulting in recordings with a lot of babble noise, degrading the speech recognition accuracy
Forced alignment module
With our reading learning application, we benefit from the knowledge of the word or sentence that the child is supposed to read. We can thus do forced alignment of the text with the audio, with a classically used model based on Gaussian Mixture Models (GMM) and Hidden Markov Models (HMM). The language model is slightly modified to fit reading learners’ speech and detect potential fluency problems, with the introduction of typical mistakes?.
Phoneme recognition module
Hybrid acoustic model architectures based on deep neural networks (DNN) and HMMs have been widely used in speech recognition this last decade. We use time-delay neural networks (TDNN), that are particularly recommended for speech recognition since they are able to model temporal relationships between acoustic events while providing shift-invariance in translation of time. As can be seen in Figure 1, context width varies depending on the layers: bottom layers learn short duration acoustic-phonetic characteristics, while top layers learn more complex features of longer duration.
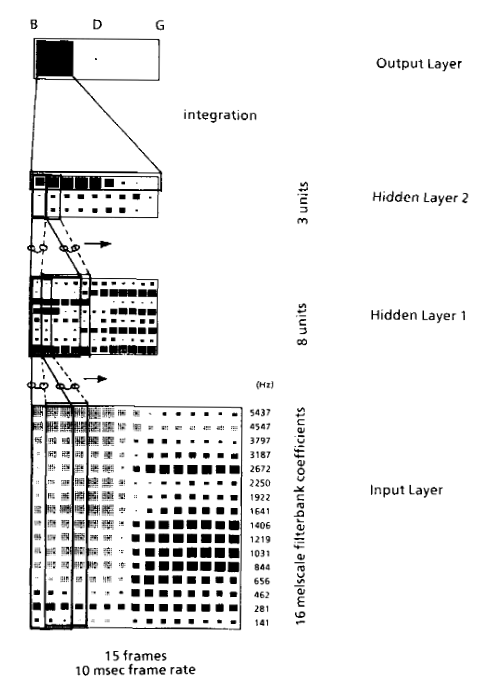
Figure 1: Architecture of the TDNN
To overcome the lack of child speech data, we use transfer learning: it consists in training a TDNN on a substantial adult speech corpus and re-training it with our small child speech corpus. Figure 2 presents the two different methods that we implemented.
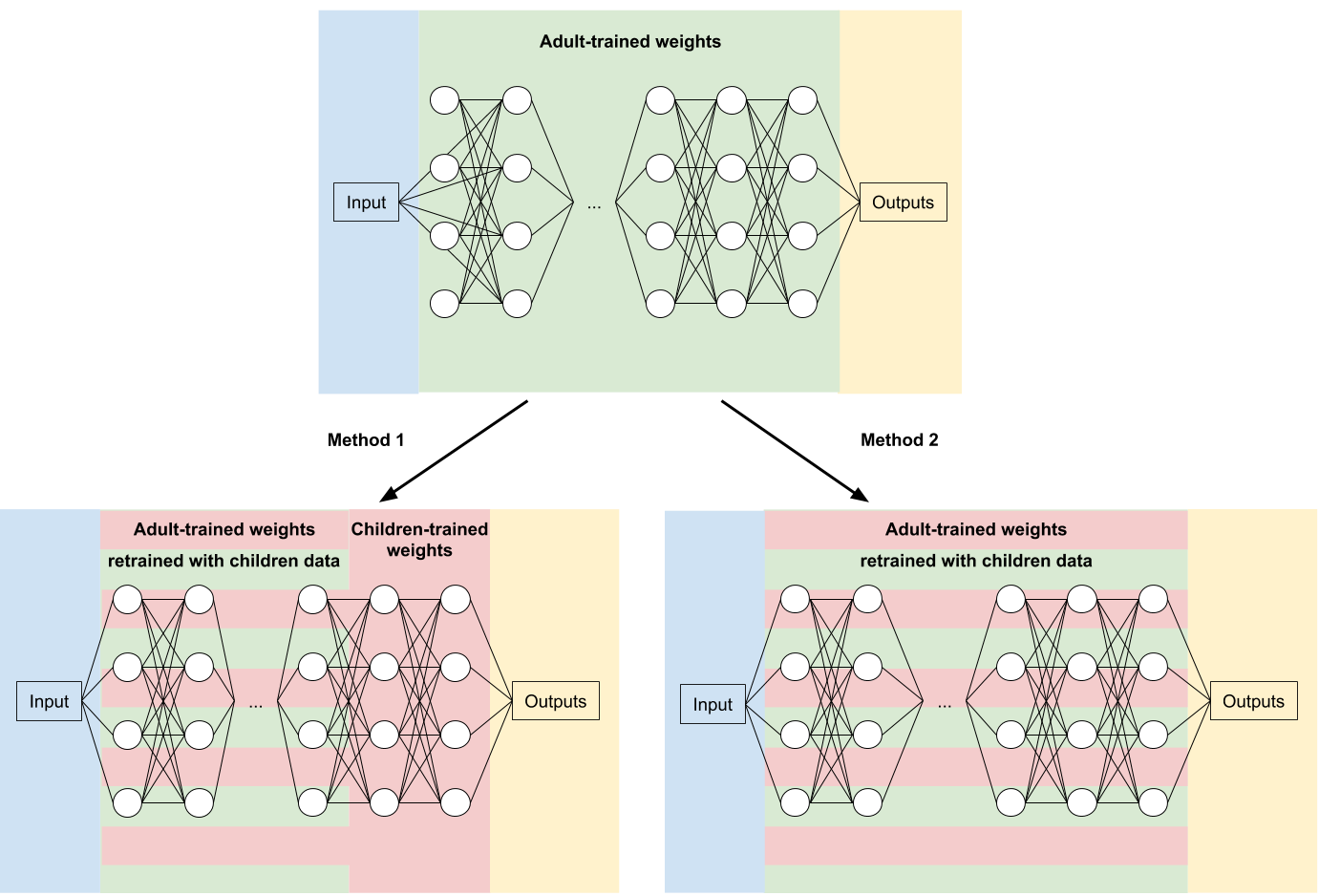
Figure 2: Schematic principle of transfer learning, with 2 different methods
An important morphological difference between adults and children is their vocal tract length, that acts on their voice’s frequency range. We use vocal tract length normalisation to further reduce the mismatch between adult and children voices: it warps the frequencies to compress or extend them to a different range.
Decision module
By comparing the outputs of the forced alignment and phone recognition modules, we compute features to feed a classifier, that decides whether a word is misread or not.
Pedagogical part
To build a comprehensive tool for teachers, it is crucial to understand their needs and the process of reading learning. A pedagogical study has been done in parallel with technical improvements, resulting in a summary of the successive steps of reading learning.
Partnership
Lalilo
Created in 2016, Lalilo, a Parisian start-up, creates a pedagogical assistant for teachers from Kindergarten to 2nd grade to help them differentiate their teaching of reading. The Lalilo platform offers reading aloud exercises for students, which uses speech recognition and machine learning to detect reading mistakes and fluency problems.
Contributors
Lucile Gelin, Julien Pinquier, Thomas Pellegrini, Morgane Daniel
References
- Gales, M., & Young, S. (2007). The Application of Hidden Markov Models in Speech Recognition. Foundations and Trends® in Signal Processing, 1(3), 195–304.
- Waibel, A., Hanazama, T., Hinton, G., Shikano, K., & Lang, K. J. (1989). Phoneme recognition using Time-Delay Neural Networks. IEEE Transactions on Acoustics, Speech, and Signal Processing, 37(3), 328–339.
- Zhan, P., & Waibel, A. (1997). Vocal Tract Length Normalization for Large Vocabulary Continuous Speech Recognition. Cmu Computer Science Technical Reports, 87(May), 97–148. link