Action on Hearing Loss
Using automatic speech recognition to predict speech-in-noise perception for simulated age-related hearing loss
Background
The most common treatment for hearing loss is the fitting of hearing aids (HAs), based on the patient’s audiometric pure-tone thresholds, to restore the audibility of those sounds the patient is no longer able to hear. However, patient satisfaction and compliance with HA prescription heavily depend on the quality and, in case of speech, the intelligibility of the amplified signals. Hence, audiological evaluations often also include measures of speech intelligibility. In order to establish the HA settings yielding maximum intelligibility, the identification task has to be repeated for each combination of HA settings. Such prolonged testing can be time-consuming and can result in increased levels of fatigue and inattention in the generally older patients, thus negatively affecting test performance. Moreover, speech intelligibility depends on the listener’s familiarity with the speech material, and so, ideally, speech material should only be used once with the same listener which might limit the number of HA settings that can be tested.
To overcome these issues, it has been suggested that automatic speech recognition (ASR), which has made important progress in recent years with the use of deep neural networks, could provide reliable and fast estimates of human speech-processing performance. Indeed, ASR systems have been successfully used to predict the intelligibility of disordered speech (Fontan et al., 2015b; Maier et al., 2009).
Recent collaborative work (Fontan et al., 2015a, 2017) between Archean Technologies and the IRIT provides first evidence that an ASR system, when combined with an appropriate language model, can predict the declines in human intelligibility in quiet that are associated with age-related hearing loss (ARHL). In these studies, young normal-hearing participants listening to French speech processed to simulate ARHL (i.e., elevated thresholds, reduced frequency selectivity and loudness recruitment) at various levels of severity. This experimental design was used so that the same stimuli could be presented to the human listeners and to the ASR system. The results for a sentence-identification task are given in the figure below.
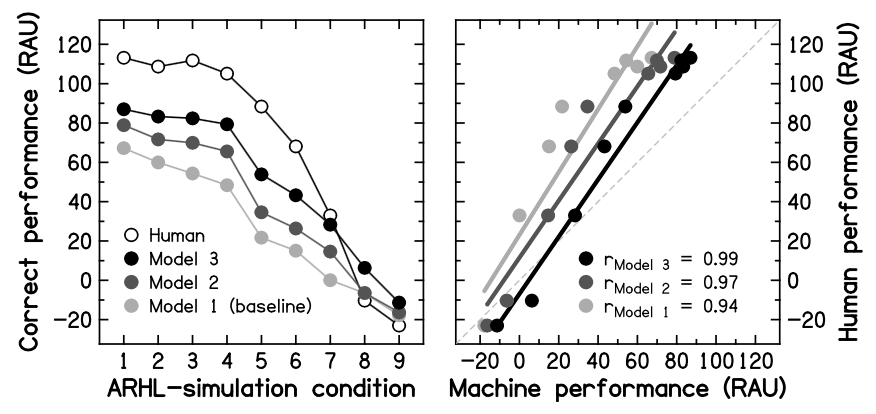
The left panel shows human and machine scores (expressed in Rationalized Arcsine Units, RAUs) as a function of the simulated level of ARHL [from 1 (very mild) to 9 (very severe)]; a baseline and two more sophisticated language models were used for the ASR system. The right panel shows the correlations between these scores. Machine scores followed the same trend as human performance with increasing level of ARHL (with correlation coefficients generally >0.9), and the use of more sophisticated language models yielded somewhat better matches to the human data.
Taken together, this preliminary work constitutes the proof-of-concept that trends in human speech perception due to ARHL can indeed be predicted on the basis of ASR systems. Therefore, it seems reasonable to assume that, in the future, such systems could also provide predictions of aided speech perception abilities in hearing-impaired listeners, thereby facilitating and improving HA fitting and, ultimately, patient comfort and satisfaction.
However, further research is needed to improve the ASR system’s ability to accurately predict performance scores, and to investigate whether phonetic confusions and the perception supra-segmental information (e.g. intonations) can be predicted by such a system (Fontan et al., 2016). Most importantly, the main complaint of people experiencing ARHL is understanding speech in acoustically challenging environments (such a busy restaurant). Thus, it is crucial to assess the applicability of ASR-based predictions to speech-in-noise processing.
Proposed activities
The purpose of the proposed project is to establish a behavioral reference database for native-English-speaking listeners against which machine predictions can be compared. In contrast to the previous work, all experiments will measure performance not only in quiet but also in the presence of different background sounds (speech-shaped noise vs. babble noise) presented at a range of signal-to-noise ratios. Recording of test stimuli and testing of participants will be performed at the Institute of Hearing Research (IHR) in Nottingham while the development, training and testing of the ASR systems will be conducted at the IRIT (Toulouse, France).
In a first study, the main and interactive effects of background noise and simulated ARHL will be systematically investigated in young normal-hearing listeners (N=50) for a range of speech materials (phonemes vs. sentences; different intonation patterns) and tasks (identification vs. comprehension). This will test whether the applicability of the ASR system can be extended: (i) from a syllable-based language (French) to a stress-based language (English), (ii) from neutral to expressive utterances, (iii) from identification to comprehension, and (iv) to the prediction of phoneme (mis)identification.
In a second study, a group of older (≥60 years) normal-hearing listeners (N=20) will be tested on a subset of the experimental conditions. Such listeners are more representative of the population for which the prediction system is ultimately designed, namely older listeners with ARHL. The latter also suffer from age-related declines in supra-threshold auditory and cognitive processing abilities which are associated with speech-in-noise perception (Füllgrabe et al., 2015). Hence, results from young listeners are less affected by those age effects, and reference data should also be obtained for older normal-hearing listeners. It is notoriously difficult to recruit such “super-hearers” from the general population but previous work by the lead applicant has already identified a number of those listeners who will be re-screened for participation in this study.
Impact & benefit for listeners with hearing impairment
This project combines expertise in auditory perception (Füllgrabe), language sciences (Fontan) and computer modelling (Farinas), and brings together academia (Universities of Nottingham and Toulouse) and industry (Archean Technologies) in an attempt to develop an objective measure of speech intelligibility. To further the reflection on the possible applications of ASR, a 1-day workshop will be organized at the IHR in June 2017. In addition to the applicants, contacted researchers working on speech prediction have already expressed their interest in attending this meeting (e.g. Dr. Ma: Hearing Research Group, University of Sheffield; Dr. Sumner: IHR). Project findings will be disseminated at an international conference and as a peer-reviewed research article. As regards the benefit for hearing-impaired listeners, the results of this project would find a natural and direct application in the treatment of hearing loss via the fitting of HAs. Archean Technologies has already developed a device that performs high-quality speech recordings directly in the patient’s ear canal. In the future, these recordings could be used as the input to an ASR system that computes an intelligibility score. If validated, such a system would constitute an objective alternative to behavioral speech tasks, providing the audiologist with quantitative and qualitative information on predicted speech processing to assist in the fine-tuning of HAs.
Participants
- Christian Füllgrabe (University of Nottingham, UK) – scientific coordinator
- Lionel Fontan (Archean Labs, Montauban)
- Jérôme Farinas
Funding
- Action on Hearing Loss is the trading name of The Royal National Institute for Deaf People. A registered charity in England and Wales (207720) and Scotland (SC038926). Registered as a charitable company limited by guarantee in England and Wales No. 454169. Registered office: 19-23 Featherstone Street, London EC1Y 8SL.
Schedule
- Start time : 1st may 2017
- End time : 31th december 2017