Présentation


Les travaux visés dans le projet CAIR s’inscrivent dans la lignée de systèmes appelés moteurs d’analyse ou moteurs de connaissances. De façon plus spécifique, l’originalité du projet CAIR réside dans sa capacité à interpréter la requête utilisateur en la situant dans son contexte, à identifier les sources de données pertinentes, à en extraire les fragments d’informations utiles et à les composer pour en former un objet ou une connaissance originale.
Le projet s'intéresse particulièrement aux requêtes suivantes:
- Requête analytique (type OLAP): produire des valeurs numériques résultat d'une analyse de sources documentaires (par exemple, h-index, omnbre de livres consultés, nombre d'offres promotionnelles)
- Requête entité : extraire les éléments saillants concernant un individu (par exemple un homme politique, un scientifique), un phénomène (ex : réchauffement climatique, migration) ou une entité concrète ou abstraite (caractéristiques d'un modèle de Smatphone)
- Requête résumé (synthèse): extraire en substance "ce qui se dit" à propos d'un personnage, d'un objet, d'un évènement (par exemple: extraire des blogs ce qui se dit sur le virus Ebola, extraire des forums les appréciations données sur un film, analyser les tweets pour suivre une rumeur,...)
Axes de recherche
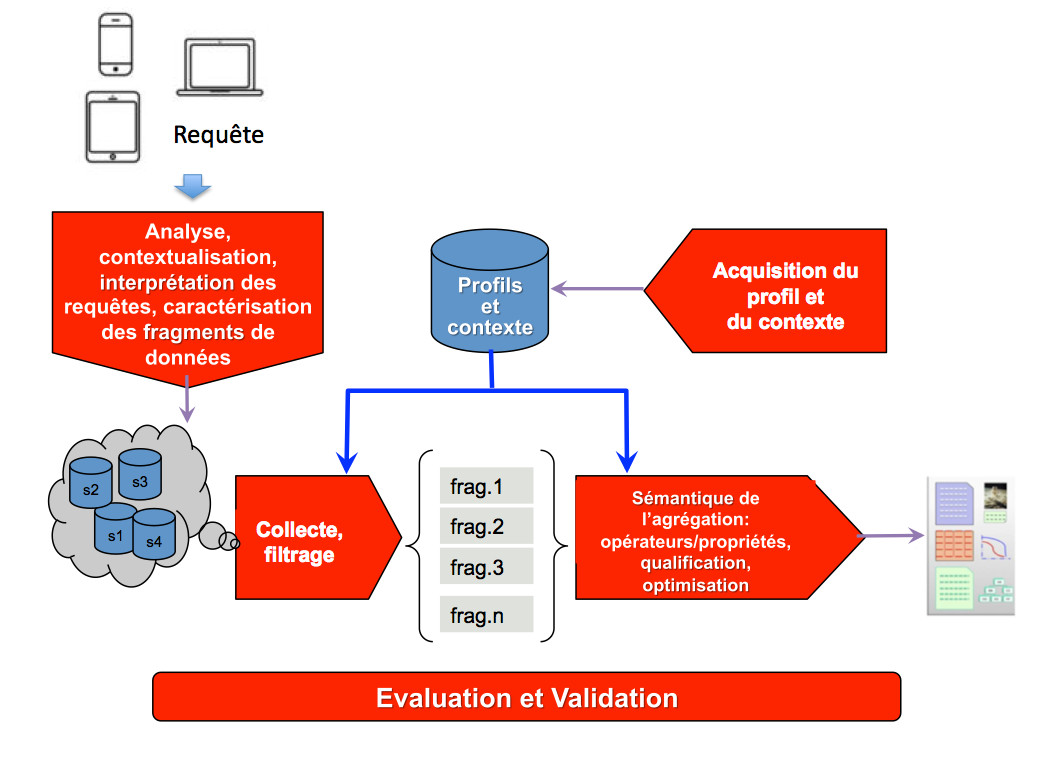
Plus précisément, le projet CAIR adressera les axes de recherche suivants :
- La capture de l’intention de l’utilisateur et l’interprétation de sa requête. Comme mentionné plus haut, la requête de l’utilisateur peut s’exprimer de diverses manières (ex., liste de mots clés, expression logique, pattern de document, graphe de concepts), mais quelle que soit son expression elle n’est qu’une représentation approchée de son besoin. Il est par conséquent indispensable d’imaginer un processus d’interprétation qui permet d’affiner la requête pour mieux appréhender le besoin et comprendre la nature et la structure des objets visés. Ce processus peut s’appuyer sur le profil utilisateur, sur son contexte ou sur d’autres connaissances du domaine ou des communautés proches de l’utilisateur. L’enrichissement, la reformulation et la décomposition de requêtes seront les opérations fondamentales de cette tâche.
- La définition d’opérateurs appropriés et des algorithmes sous-jacents pour répondre aux requêtes agrégatives. Il s’agit d’élaborer un ensemble pertinent d’opérateurs permettant de construire des objets intelligibles à partir de fragments hétérogènes émanant de plusieurs sources de données. Bien que dépendant
- de chaque type de requêtes, cet ensemble devrait comporter les opérateurs suivants : sélection de fragments, élimination de fragments redondants, composition de fragments, etc. La composition de ces opérateurs formera un processus complexe qui doit être validé par des métriques telles que la cohésion d’un ensemble de fragments, la diversité des fragments, la pertinence de l’objet obtenu par rapport au besoin de l’utilisateur.
- La définition de la notion de pertinence et des métriques associées. La problématique concerne la définition d’un modèle de pertinence (à l’image des modèles de recherche d’information) qui rend compte de la pertinence ou de la qualité d’un agrégat par rapport la requête de l’utilisateur.
- L’optimisation du processus d’agrégation. Un niveau de complexité du problème d’agrégation réside dans la combinatoire nécessaire pour former les objets agrégés à partir des fragments sélectionnés. Nous analyserons les problèmes critiques et nous chercherons à concevoir des techniques basées par exemple sur des algorithmes et métaheuristiques pour réduire cette combinatoire.
- L’évaluation et la validation de nos propositions. A notre connaissance, il n’existe à ce jour ni de cadre (benchmark) ni de protocole d’évaluation pour caractériser la qualité de la recherche agrégative. La définition d’un référentiel de validation accepté par une communauté reste un but incontournable pour la validation des propositions. Nous nous engageons, comme nous l’avons fait dans les projets précédents, à investir dans la mise en place de telles plateformes et à mettre en oeuvre un ensemble de scénarios de validation selon les types de requêtes adressés.