Blind Audio Source Separation - Speech
We deal with the case where the sources are linearly mixed and the
mixtures are underdetermined. Hence, A has more columns than rows.
Sparsity of the sources is vital for good separation. Bayesian methods
such as the Gibbs Sampler (a standard MCMC simulation method) are used
to estimate the sources and the mixing matrix in the presence of noise.
I.I.D. Gaussian noise was added to the observations, which resulted in
an SNR of about 16 dB. The mixing matrix used is given by A = [0.4000
0.8315 0.5657; -0.6928 -0.3444 0.5657].
2) Speech Signals
These are the 3 speech signals.
Speech Signal 1
"While the Jeffers had reached its limit, it was now mid-August, which
meant he had been separated from Marshall from..."
Speech Signal 2
"From the playground of the world, there was no... place like it, in
the whole world, like coning out when I was a youngster."
Speech Signal 3
"Get ready for the dynamic impact test, where we'll really put your
audio system through its paces to show you what it can do."
These are the 2 mixtures.
Mixture 1
Mixture 2
Sparsity Indices for various transform types.
Click on thumbnails for larger (and clearer) versions.
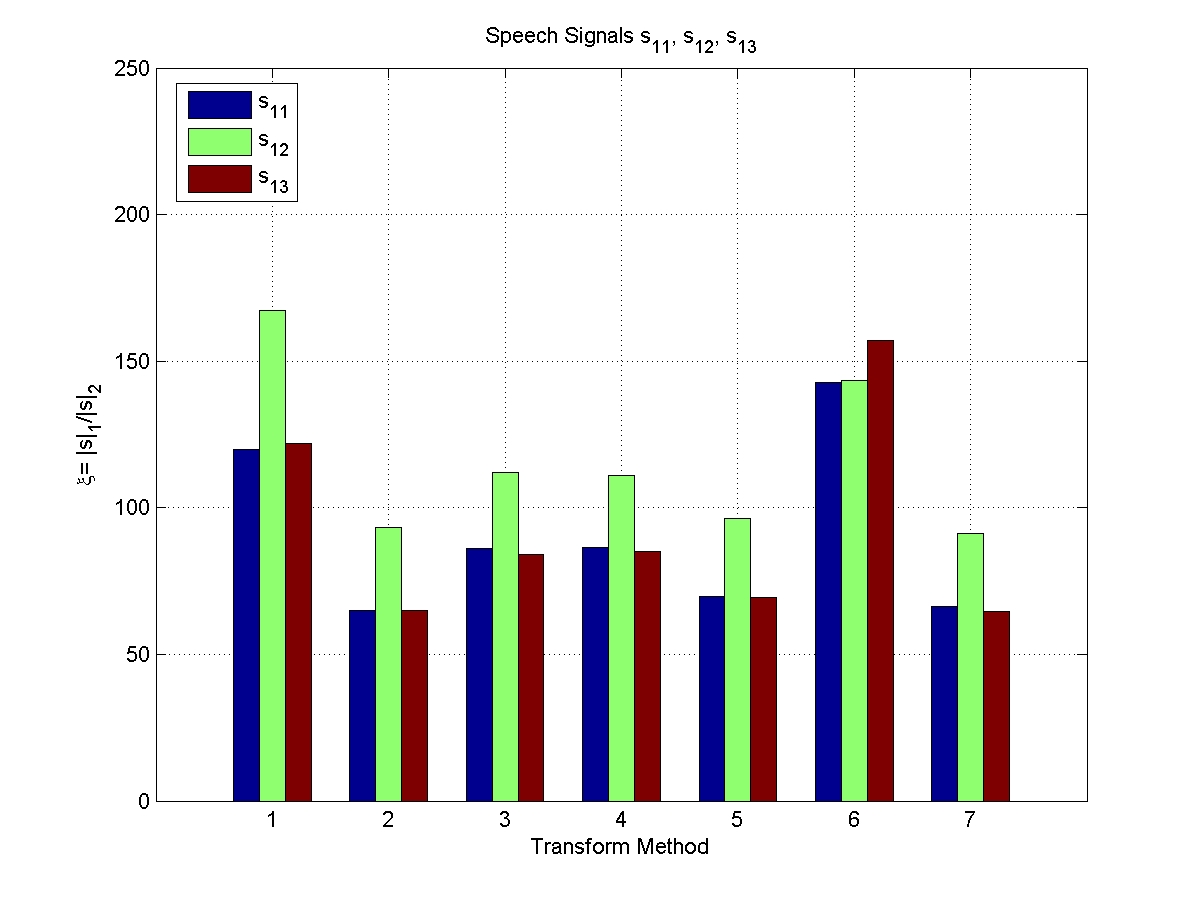
Transform Types
| 1 |
2 |
3 |
4 |
5 |
6 |
| DCT |
MDCT |
WT (Vai) |
WT (Sym8) |
WPBB |
No Transform |
Results at a glance.
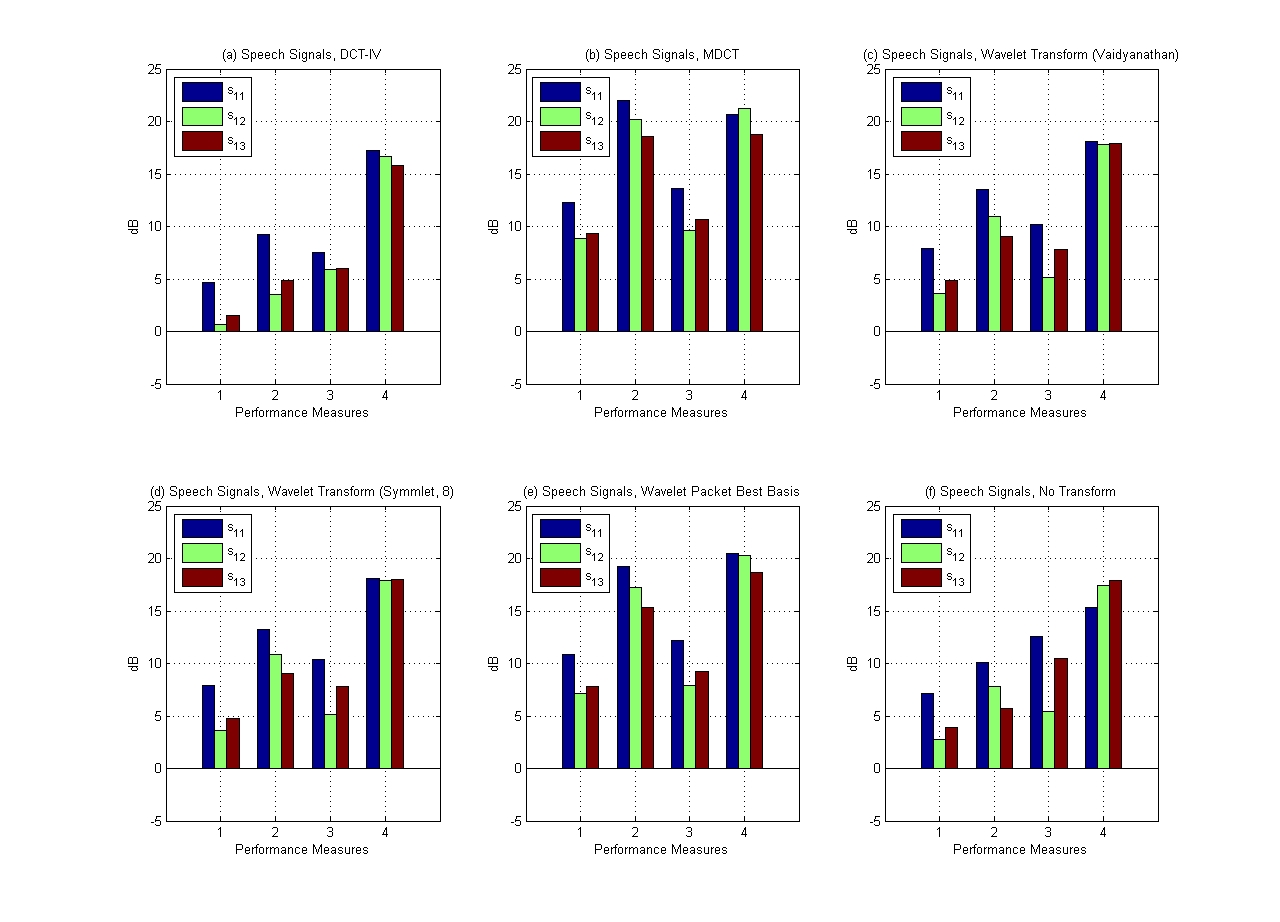
Performance Measures
| 1 |
2 |
3 |
4 |
| SDR |
SIR |
SAR |
SNR |
2.1) Discrete Cosine Transform
Reconstructed Speech Signal 1
Reconstructed Speech Signal 2
Reconstructed Speech Signal 3
Virtually no separation even after convergence was observed.
2.2) Modified Discrete Cosine Transform
Reconstructed Speech Signal 1
Reconstructed Speech Signal 2
Reconstructed Speech Signal 3
Very good separation.
Signals 1 and 3 contain noticeable but limited anomalous artifacts.
But, even the chirping of the birds can be heard clearly in Signal 2.
2.3) Wavelet Transform: Vaidyanathan
Reconstructed Speech Signal 1
Reconstructed Speech Signal 2
Reconstructed Speech Signal 3
Wavelets are not the right basis to use for separation of speech
signals.
Very distinct artifacts.
2.4) Wavelet Transform: Symmlet 8
Reconstructed Speech Signal 1
Reconstructed Speech Signal 2
Reconstructed Speech Signal 3
Wavelets are not the right basis to use for separation of speech
signals.
Very distinct artifacts.
2.5) Wavelet Packet Best Basis
Reconstructed Speech Signal 1
Reconstructed Speech Signal 2
Reconstructed Speech Signal 3
An adaptive basis does very well but not as well as the MDCT in terms
of noise suppression.
You have to listen really carefully before you can come to a conclusion
that this is not as good as the MDCT.
2.6) No Transform
Reconstructed Speech Signal 1
Reconstructed Speech Signal 2
Reconstructed Speech Signal 3
Surprisingly, applying the Gibbs Sampler on the sources directly,
without performing the transform, also results in some separation.
Back
Next
Home
Server at www.eng.cam.ac.uk