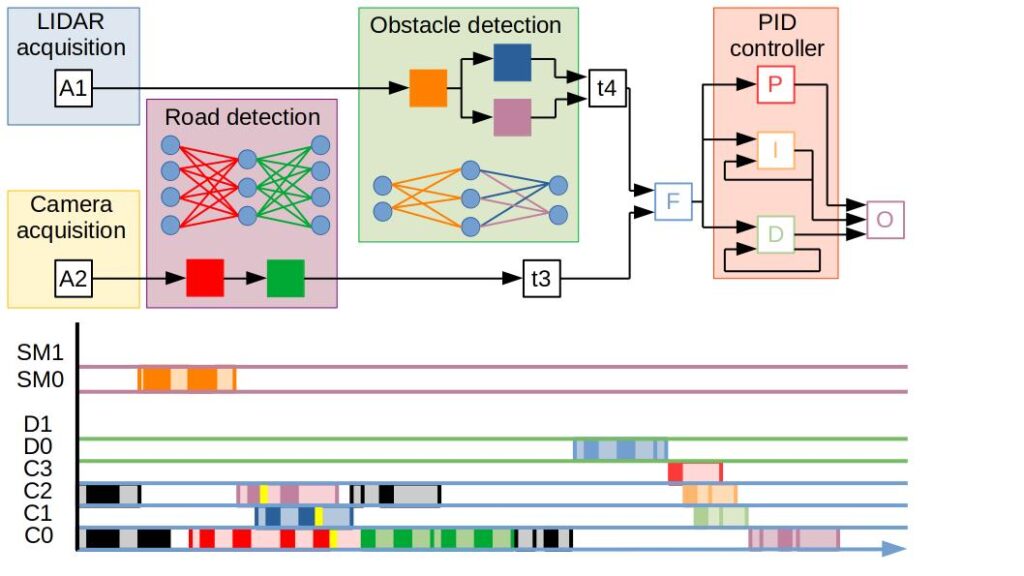
MeSCAliNe is a JCJC ANR project going on from April ’22 to February ’26. The main objective of the project is to develop techniques that combine static analysis, scheduling and compilation in order to manage the real-time aspects of applications deployed on parallel architectures such as multi/many-core CPUs and GPUs.
This project takes place in the context of the deployment of AI applications in critical embedded systems, such as autonomous vehicles. These applications are computationaly intensive and put a significant pressure on the memory system. In order to speed up their execution, we benefit from the parallel nature of the computations by deploying them on parallel architectures. However, these architectures raise particular problems for real-time analysis techniques. Components such as buses and memory controllers are shared between cores in multicore architectures, making the worst-case execution time of the applications functions execution context-dependent (in particular it depends on the functions scheduled in parallel on other cores). The use of GPU accelerators raises other problems linked to the closed nature of these architectures and to their particular execution model (SIMT): to this day there exists no satisfactory worst-case execution time analysis technique for GPUs.
MeSCAliNe aims at progressing on both fronts (fine-grain CPU interference handling and GPU analysis) by elaborating a unified method based on the Time Interest Points (TIPs) methodology, which tighly intricates static analysis, scheduling and code generation techniques.