Audio Fingerprinting for TV channel detection in real time
Context
Television still has a strong impact on society and consumers.
Social TV or social television is a blend of social media and television activity.
A growing number are watching television programs on multiple devices, across computers, mobile phones, and tablets.
Nowadays, applications can use this second screen to improve TV’s experience.
For example, customers can participate in a chat, ask questions during a debate or share an extract of the video viewed.
As part of an internship proposed by Telequid and supervised by SAMoVA, a prototype of the mobile app which identifies a TV channel with audio recording was developed.
The goal is to use the second screen microphone to automatically connect an app to the good TV channel.
In this work, we evaluated existing fingerprinting methods and adapted some of these methods to detect which TV channel is being watched, using audio recorded with a smartphone or tablet.
Audio fingerprinting objective is to obtain a noise-robust condensed digital summary from audio. Then, to identify it, a search and matching are done in a database of audio previously “fingerprinted”. The database is composed of audio flux from TV and they are noise-free. The query from the phone has to match a channel in the database which is updated continuously. Furthermore, the queries from the phone are noise distorted by the environment and also by the microphones. The system has to be able to work with all phones or at least the most popular ones. Moreover, we have to deal with different distances to the microphone.
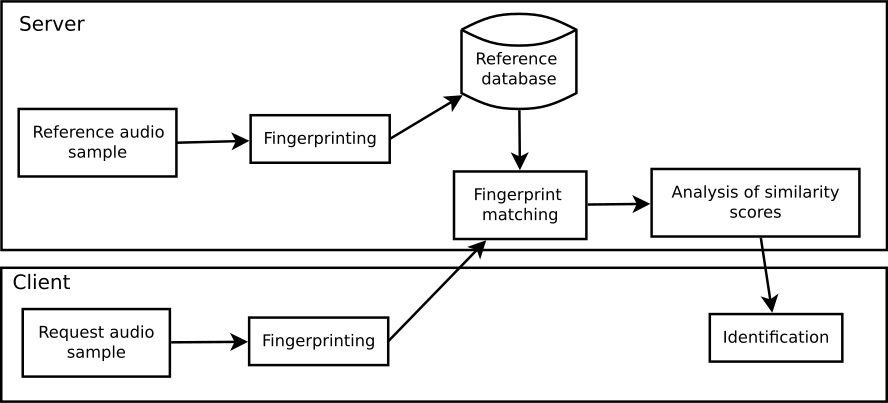
Overview
Philips fingerprinting method
This method was created by Haitsma and Kalker [8] while they were working for Philips company. Based on critical bands, this method provide good results, around 87 % on our database. We’ve made a system inspired by this method following this logic :
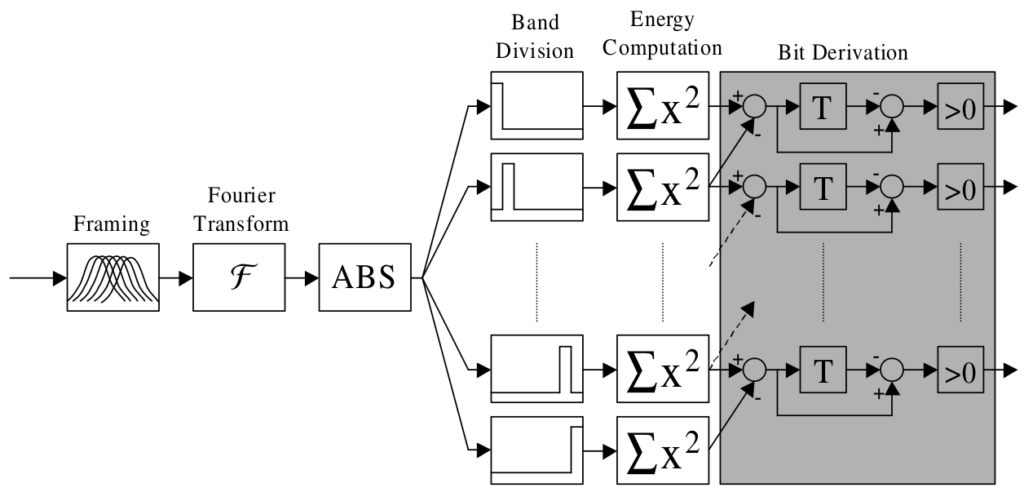
The search in the database of the fingerprint is carried out through a hashtable. Each sub-fingerprint can be converted into hexadecimal values (the hash value). The search consists of finding all exact matches between a sub-fingerprint of the query, and the database. Once sub-fingerprint are matched, a binary distance (Hamming) is performed between the query, and the extract of the TV channel where the good sub-fingerprint is located. If the binary distance is under some value, the channel is identified
Audio fingerprinting method
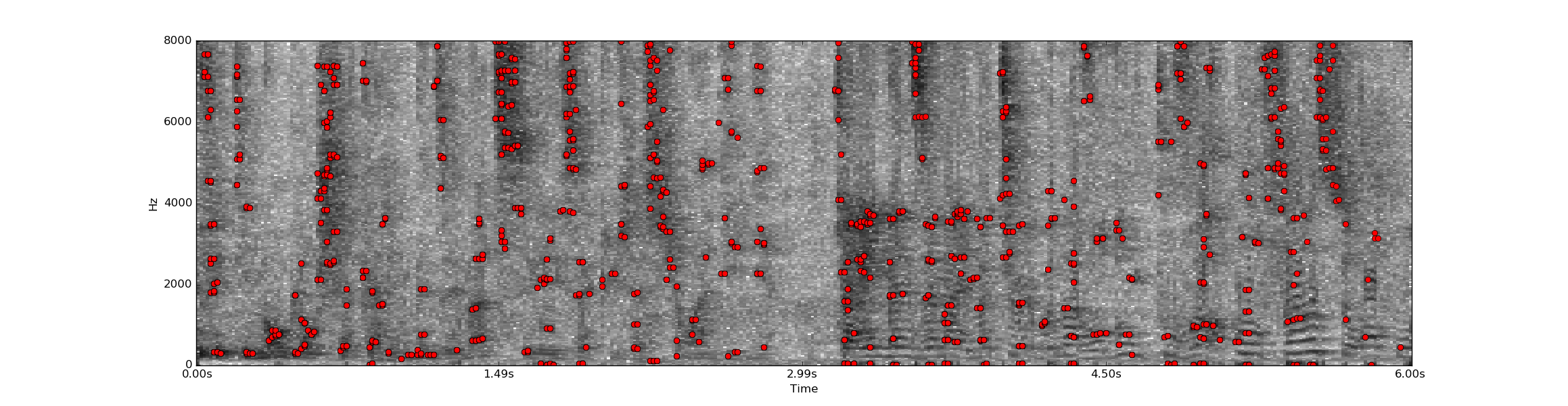
This method was created by Courtenay V. Cotton and Daniel P. W. Ellis [4]. The implementation we use is an modified version of their original code which is now totally adapted to TV signal and real-time. This method is based on the match of energy peaks in the spectrogram which are linked by pairs. This method provide the best results, around 98 % on our database.

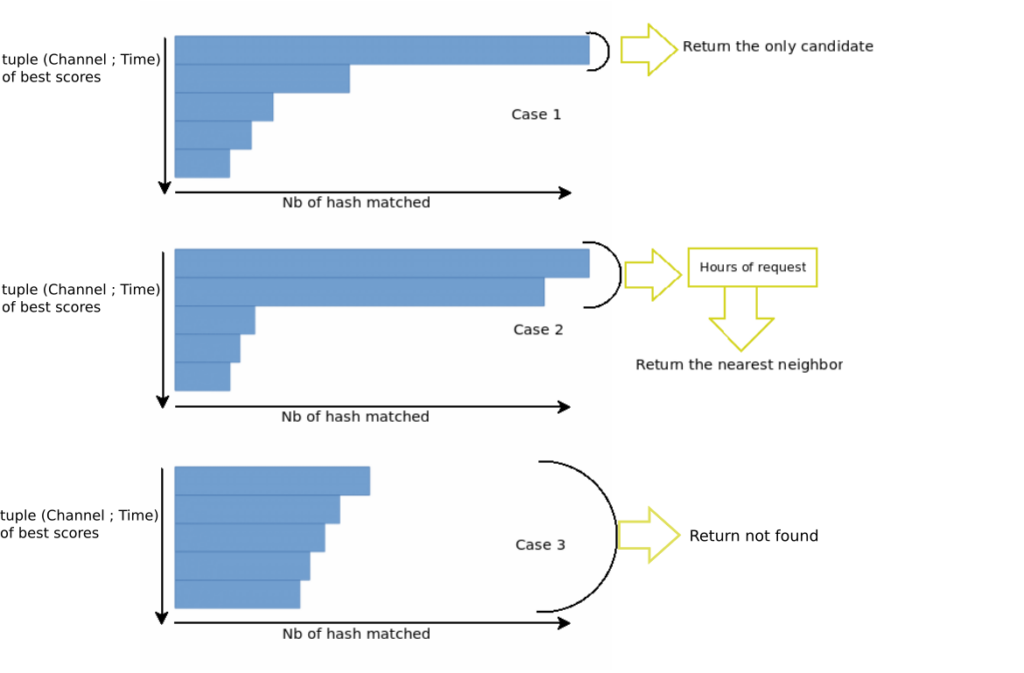
To match the query fingerprint with the database, the number of exact matches of hash is calculated. To select the best answer, a decision strategy filters the N-best scores, to correct some matching mistakes, occurring by example when the same publicity is present on different channels.
The Below images show the audio signal, the detection of peaks and hash that match the database

System
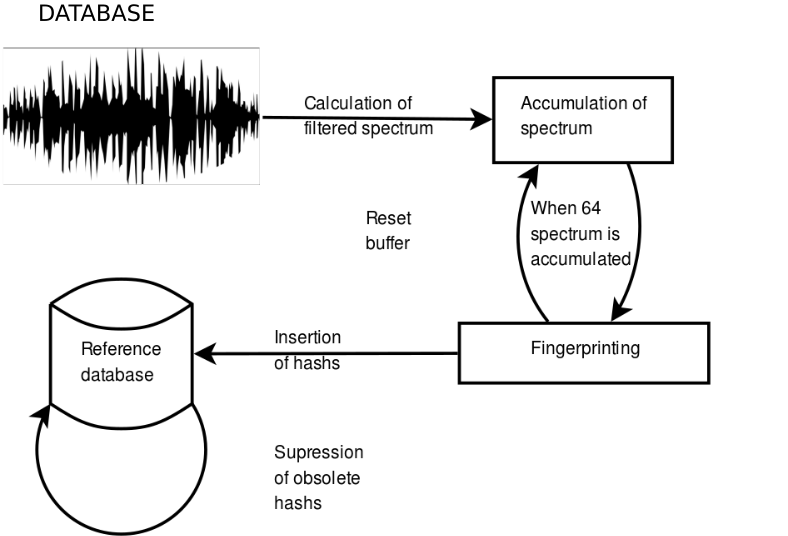
To be able to use audio fingerprints in real time, we have transformed the query and the database to make them dynamic. In the case of TV channel detection, we do not want to recognize an audio file stored in a database. We want to detect the current television channel. So we need to update the database in real time. The overall system architecture is shown in the figure below.
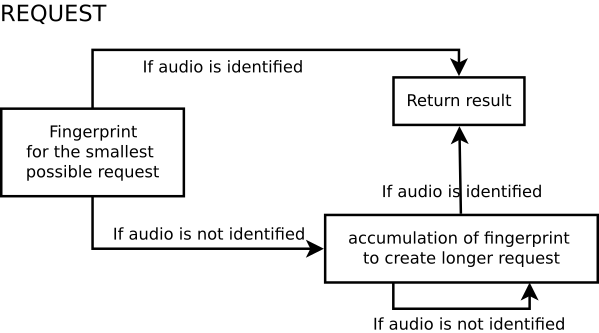
To reduce the time required to detect a query, several identification attempts are made, resulting in a dynamic fingerprint.
Results
Our databse is composed of 24 channels from french TV and 3 from anglophone country. Our query set is made by about 20.000 audios of 6 seconds extract from sounds registered from different phones at different distances. Half of them are noisy. The noise has been made by playing another tv while registering or with ambiant noise as human voices or door slam, etc … With dynamic fingerprint (audfprint like),we obtained 97,8% of good TV chanel detection, 0.1% of false detection and 2.1% of non detection. In 85.72% of cases, only 2 seconds are enough to find the good TV channel.
Contributors
Lucien Mahot (M2 Image et Multimedia, Student)
Sebastien Ferreira (M2 Intelligence Artificielle et Reconnaissance des Formes, Student)
Julien Pinquier (Assistant professor and team leader SAMOVA – IRIT)
Jérome Farinas (Assistant professor – IRIT)
References on audio fingerprinting.
[1] M. Camus, “Identification audio pour la reconnaissance de la parole,” Ph.D. dissertation, Université Paris DESCARTES, 2011.
[2] N. Chen, H. Xiao, and W. Wan, “Audio hash function based on non-negative matrix factorisation of mel-frequency cepstral coefficients,” IET Information Security, vol. 5, no. 1, pp. 19–25, 2011. [Online] Available: http://dx.doi.org/10.1049/iet-ifs.2010.0097.
[3] A. L. chun Wang and T. F. B. F, “An industrial-strength audio search algorithm,” in Proceedings of the 4 th International Conference on Music Information Retrieval, 2003.
[4] C. V. Cotton and D. P. W. Ellis, “Audio fingerprinting to identify multiple videos of an event,” in Proc. IEEE Int. Conf. on Accoustics, Speech and Signal Processing (ICASSP), 2010, pp. 2386–2389.
[5] N. Q. K. Duong and F. Thudor, “Scalability issues in an hmm-based audio fingerprinting,” in Proc. IEEE Int. Conf. on Multimedia and Expo, 2004, pp. 735–738.
[6] S. Fenet, G. Richard, and Y. Grenier, “A Scalable Audio Fingerprint Method with Robustness to Pitch-Shifting,” in ISMIR, Miami, United States, Oct. 2011, pp. 121–126. [Online] Available: https://hal-institut-mines-telecom.archives-ouvertes.fr/hal-00657657.
[7] M. M. Hendrik Schreiber, Peter Grosche, “A re-ordering strategy for accelerating index-based audio fingerpriting,” in 12th International Society for Music Information Retrieval Conference , 2011.
[8] Haitsma, Jaap, and Ton Kalker. “A highly robust audio fingerprinting system.” Ismir. Vol. 2002. 2002.
[9] C. H. N. Q. K. Duong and Y. Legallais, “Fast second screen tv synchronization combining audio fingerprint technique and generalized cross correlation,” 2013, pp. 241–244.
[10] T. K. P. Cano, E. Batlle and J. Haitsma, “A review of algorithms for audio fingerprinting,” in IEEE Workshop on Multimedia Signal Processing, 2002, pp. 169–173.
[11] G. Peeters, “A large set of audio features for sound description (similarity and classification) in the cuidado project,” in CUIDADO I.S.T. Project Report, avril 2004.
[12] A. Ramalingam and S. Krishnan, “Gaussian mixture modeling of short-time fourier transform features for audio fingerprinting,” no. 4, pp. 457–463, 2006.
[13] M. S. V. Chandrasekhar and D. A. Ross, “Survey and evaluation of audio fingerprinting schemes for mobile query-by-example applications,” in 12th International Society for Music Information Retrieval Conference (ISMIR), 2011, pp. 801–806.