Pseudo Syllable
Context
The notion of “Pseudo Syllable” was introduced to analyze language rhythms. This was intended for use in the prosodic module of our Automatic Language Identification system. Its relevance is confirmed by the results obtained on multilingual languages discrimination tasks. The concept can be applied on other research field, and in particular on multlingual system, where language specific syllable segmentation cannot be performed.
Overview
From a prosodic point of view, languages differ in their rhythm and intonation. Syllable is a first-rate candidate for rhythm modeling. Unfortunately, segmenting speech in syllables is typically a language-specific mechanism and thus no language independent algorithm can be derived. For this reason, we introduced in [Farinas & Pellegrino, 2001] the notion of “Pseudo Syllable” derived from the most frequent syllable structure in the world, the Consonant-Vowel structure (see the work of Dauer, 1983). In our algorithm, the speech signal is parsed in patterns matching the .CnV. structure, where n is an integer that may be zero and V may result from the merging of consecutive vowel segments.
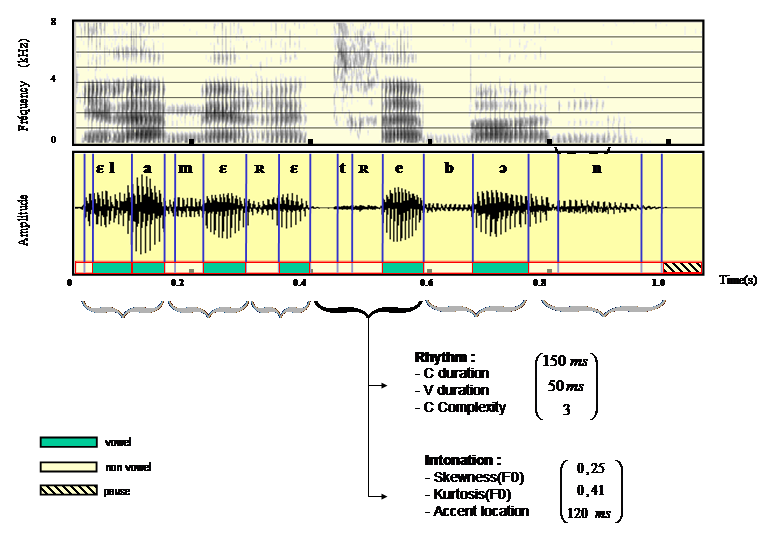
Figure 1. Example of Pseudo Syllable parsing on the french utterance “Et la mer est très bonne”.
For example, if the vowel detection algorithm produces the sequence (CCVVCCVCVCCCVCVCCC), it is parsed in the following sequence of 5 pseudo- syllables: (CCV.CCV.CV.CCCV.CV). The last syllable is discarded as it does not contains any vowel, and the two adjacent vocalic segments in the firsrt Pseudo Syllable are merged.
Pseudo-syllable description
Both rhythmic and fundamental frequency features are computed to describe each Pseudo-Syllable. The parameters used are described below.
Rhythmic features
For each pseudo-syllable, three parameters are computed, corresponding respectively to the total consonant cluster duration, the total vowel duration and the complexity of the consonantal cluster. For example, the description for a .CCV. pseudo- sequence is: P(.CCV.)={Dc; Dv; Nc}, where Dc is the total duration of the consonantal segments, Dv is the duration of the vowel segment and Nc is the number of segments in the consonantal cluster (in the above example, Dc = 150ms, Dv = 50 ms and Nc = 3). Such a basic rhythmic parsing is obviously limited, but provides a framework to model rhythm that requires no knowledge on the language rhythmic structure
Fundamental frequency features
The fundamental frequency outlines are used to compute statistics inside of the same pseudo-syllable frontiers than those used for rhythm modeling, in order to model the intonation of each pseudo-syllable. We choose to compute statistics until 4th order (mean, standard deviation, skewness and kurtosis), in order to describe the variations of intonation within a pseudo-syllable.
Applications
Projects
- MISTRAL Project (ANR 2006 Technologies Logicielles): An open source biometric authentification framwork (with LIA, LIG, LIUM, EURECOM, Thales, Calistel)
- European Lid (Emergence 2000) 2000-2003: Language Identification on European languages (with DDL, ISC, UC Berkeley)
- Afro-asiatic Lid (APN SHS-CNRS 2000-2002): Language Identification on Afro-asiatic languages and dialects (with DDL, ISC, UC Berkeley)
- DGA (1996-1998): multilingual discrimination (with ICP, ILPGA, DDL)
Contributors
Main publications
- Jérôme Farinas, François Pellegrino. Comparison of two approaches to Language Identification. In : 7th International Conference on Speech Communication and Technology (Eurospeech’2001), Aalborg, Danemark, 03-07/09/2001, Vol. I, International Speech Communication Association (ISCA), p. 399-402, september 2001. Web link
- Jean-Luc Rouas, Jérôme Farinas, François Pellegrino, Régine André-Obrecht. Rhythmic unit extraction and modelling for automatic language identification. In : Speech Communication, Elsevier, Vol. 47 N. 4, p. 436-456, 2005. Web link