
Audio Segmentation
Context
One of the most difficult tasks in speech processing is to define limits of the phonetic units present in the signal. Phones are strongly co-articulated and there are no clear borders among them, so the link between the linguistic and the acoustic segmentation is not simple to define. It does not matter which code level is chosen (word, syllable, phon): the acoustic variability of speech signal makes difficult all alignment efforts and its ambiguity challenges all proposed definitions.
Overview
We have developed an audio segmentation algorithm based on the acoustic signal level.
Forward backward segmentation
This segmentation is provided by the Forward-Backward Divergence algorithm, which is based on a statistical study of the acoustic signal.
Assuming that speech signal is described by a string of quasi-stationary units, each one is characterized by an auto regressive (AR) Gaussian model. The method consists in performing a detection of changes in AR models. Two AR models M0 and M1 are identified at every instant, and the mutual entropy between these conditionnal laws allows to quantify the distance between them. M0 represents the segment from last break in the signal while M1 is a short sliding window starting also after last break. When the distance between models change more than a certain limit, a new break is declared in the signal. The algorithm detects three sorts of segments: shorts or impulsive, transitory and quasi-stationary. In fig. 1 we show an example of the segmentation where infra-phonetic units are determined.
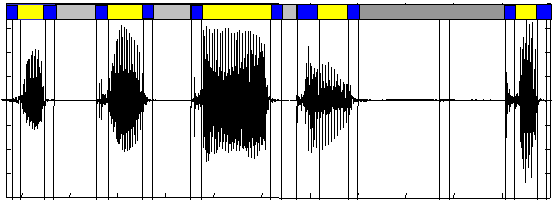
Fig 1. Results of speech segmenting algorithm
The use of an a priori segmentation partially removes redundancy for long sounds, and a segment analysis is relevant to locate coarse features. This approach have given interesting results in automatic speech recognition: experiments have shown that segmental duration carry pertinent information.
Applications
- An analyse of speech segments can be performed:
- A unique parameter vector can be extracted to identify each segment. For example, we process vectors from the middle of the segments to achieve segment labeling in one of three phonetic classes: silence, consonant or vowel.
- Segment lenght is a source of information. Music/Non music macrosegments can be indexed following this analysis.
- Pseudo-syllable. After consonant/vowel segment identification is performed, a “pseudo-syllable” unit is derived for characterising the syllable structure of the phrase.
- Audio-visual recognition. When speech segments are synchronized with lips images, acoustic information is mapped to an articulatory space. For each segment we obtain a vector representing a lip observation.
Contributors
- Régine André-Obrecht (contact)
- Patrice Pillot
- Julien Pinquier
- Maxime Le Coz
Main publications
Régine André-Obrecht. A new statistical approach for automatic speech segmentation. Dans : Transactions on Audio, Speech, and Signal Processing, IEEE, Vol. 36 N. 1, p. 29-40, 1988.
Julien Pinquier, Régine André-Obrecht. Audio Indexing: Primary Components Retrieval – Robust Classification in Audio Documents. Dans : Multimedia Tools and Applications, Springer-Verlag, Vol. 30 N. 3, p. 313-330, septembre 2006.
Jean-Luc Rouas, Jérôme Farinas, François Pellegrino, Régine André-Obrecht. Rhythmic unit extraction and modelling for automatic language identification. Dans : Speech Communication, Elsevier, Vol. 47 N. 4, p. 436-456, 2005.