TP3: Un peu d'analyse de données¶
On va faire un peu d'analyse de données, avec ou sans numpy et ses matrices.
Au passage, on va voir comment faire un peu de visualisation en Python, en utilisant le module matplotlib (librairie en plus, mais disponible avec tous les outils scientifiques)
La commande essentielle, plot, prend deux listes de coordonnées (abscisses et ordonnées), et trace la courbe correspondante reliant les points. Spyder gère automatiquement l'affichage dans sa console IPython.
%matplotlib inline
from IPython.display import Image
import matplotlib.pyplot as plt
plt.plot([1,2,3,4,5],[1,4,9,16,25])
print("Parabole:")

En option, on peut définir une couleur et une forme avec une chaine en 3e argument ("r" pour red, "o" pour un point)
plt.plot([1,2,3,4,5],[1,4,9,16,25],"ro")
print("Parabole")

#quelques variantes
plt.plot([1,2,3,4,5],[1,4,9,16,25],"bX",markersize=15,alpha=0.5)
print()

Pour contrôler un peu l'affichage, on peut fixer les extrémités des axes, et les forcer à être à la même échelle
plt.xlim(0,25)
plt.ylim(0,25)
plt.axes().set_aspect('equal')
plt.plot([1,2,3,4,5],[1,4,9,16,25],"ro")
print("Parabole encore")

Première partie: classification¶
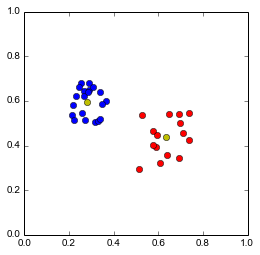
Passons maintenant aux choses sérieuses. On va considérer que l'on a des données de deux types différents (appelons les "rouge" et "bleu"), caractérisées par deux valeurs entre 0 et 1. On pourrait alors avoir une visualisation comme ceci:
Image(filename="blobs2.png")

Le but de ce TP est de définir un moyen de "classer" une nouvelle donnée pour dire si elle est plutôt de la classe bleue ou rouge.
Pour cela, un moyen simple (voire simplet, mais vous creuserez la question au 2e semestre), est de calculer le barycentre
(centre de gravité) des points de chaque classe, ici en jaune:
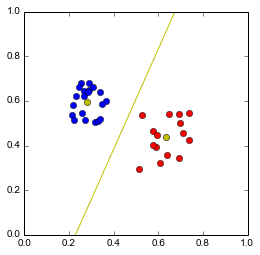
Puis de considérer leur médiatrice:
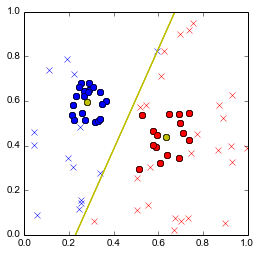
En enfin de considérer que tout ce qui est du même côté que le groupe bleu/rouge doit être bleu/rouge:
Evidemment, ça ne marchera pas pour tout type de données:
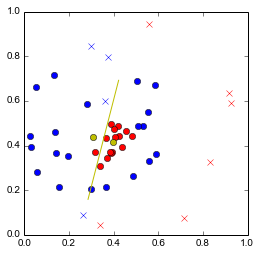
Cette méthode nécessite que les données soit séparables linéairement. Mais passons. Votre tâche:
en utilisant la fonction random.random(), faire une fonction qui génère un "nuage" de n points autour d'une position donnée ($x_0$,$y_0$), avec un étalage réglable (distance maxi par rapport à la position donnée). Par exemple, la figure initiale a été générée avec les paramètres (vous être libre du nom de la fonction):
g1 = blob(0.3,0.6,20,scale=0.1)
g2 = blob(0.6,0.4,15,scale=0.15)
La fonction renvoie juste les coordonnées.
Ecrivez aussi une fonction qui prend la sortie de "blob" et fait la figure du nuage en utilisant plt.plot
Ecrivez une fonction qui détermine le centre d'un groupe
Voici une fonction qui calcule le séparateur de deux groupes (la médiatrice): pour cela il suffit de renvoyer un point de la droite, par exemple le milieu M des centres des 2 groupes, et un vecteur normal à la droite $\vec{w}$ (par exemple le vecteur défini par les deux centres). La fonction suppose que la fonction "centre" a déjà été écrite, et que g1, g2, c1 et c2 sont des vecteurs ou matrices numpy. Adaptez si vous avez fait différemment pour les fonctions blob et centre.
La fonction qui affiche le séparateur est donnée aussi
def separateur(g1,g2):
"""renvoie le milieu du segment qui relie les centres de g1 et g2, et un vecteur directeur de la médiatrice"""
c1 = centre(g1)
c2 = centre(g2)
m = 0.5*(c1+c2)
c1x, c1y = c1
c2x, c2y = c2
return (m,(c1x-c2x,c1y-c2y))
def plot_separateur(m,w,scale=3):
"""à partir d'un point M et un vecteur directeur w, trace un segment de la droite correspondante
(échelle/scale à ajuster selon la figure)
"""
tw = (-w[1],w[0])
plt.plot([m[0]+scale*tw[0],m[0]-scale*tw[0]],[m[1]+scale*tw[1],m[1]-scale*tw[1]],"y-")
Ceci devrait vous aider à générer une figure similaire à celle-ci:
Ecrivez une fonction qui classifie un point P par rapport à cette droite: ici le critère est déterminé par rapport à l'angle entre $\vec{MP}$ et $\vec{w}$, soit $cos(\vec{MP},\vec{w})>0$ (ou inférieur), ou encore $\vec{MP}\cdot\vec{w}>0$ (ou inférieur).
Ensuite générer des points au hasard avec des coordonnées entre 0 et 1, et afficher les comme des croix (symbole 'x') avec la couleur correspondant à la classe prédite par la fonction précédente.
Deuxième partie: de "vraies" données¶
Vous pouvez maintenant utiliser le fichier "iris.txt", en annexe du sujet. Celui-ci contient des caractéristiques de différentes fleurs de l'espèce iris, réparties en trois sous-espèces "setosa", "virginica", "versicolor".
Vous pouvez utiliser numpy pour lire directement les données:
import numpy as np
data = np.genfromtxt('iris.txt', dtype=None,delimiter=',',names=True,encoding=None)
Si on regarde le résultat, on voit que cela donne une matrice de tuples, avec les caractéristiques et la classe de chaque instance. On a aussi une liste de noms des "colonnes" de ces données:
data[:4]
On peut alors récupérer les colonnes par leur nom:
data["classe"][:10]
data["sepal_l"][:10]
A vous de jouer, pour:
- Faire une fonction qui affiche 2 caractéristiques choisies sur ces données, donnant une couleur différente à chaque groupe. Utilisez les fonctionalités de numpy. Par exemple:
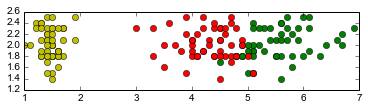
- Appliquer la première partie pour trouver des séparateurs des données, en considérant qu'il faut un séparateur pour chaque groupe par rapport aux deux autres ensembles (toujours restreint à deux caractéristiques). Trouver les 2 meilleures caractéristiques à prendre pour une bonne séparation.
- Tester vos "modèles" en calculant les séparateurs avec un sous-ensemble aléatoire des données, et en évaluant s'ils classent correctement les données restantes.
Et voilà, vous avez fait votre premier programme qui apprend automatiquement ...