
Multimodal Spatio-temporal clustering
Context
Based on the idea that TV series – which tend to have more and more complex plot, with numerous characters and multiple intertwined stories – are already segmented into narrative themes in post-production, we present a system able to discover the structure of an episode without a priori knowledge.
The system proceeds by segmenting the episode into shots, then by grouping related consecutive shots into semantic scenes and finally by clustering those scenes into stories.
- Shot : video sequence taken without interruption.
- Scene : group of consecutive shots describing temporally continuous and semantically coherent events.
- Story : group of scenes, not necessarily contiguous, showing a strong semantic relation.
We have called plot de-interlacing the process of clustering scenes as it aims at extracting interlaced stories from a single video, each of them focusing on different semantic information of the whole video plot. As this structuring approach is mostly relevant for fictional videos, our work focuses on recent TV series that have multiple threads of narration.

Exemple of expected (groundtruth) and automatic (hypothesis) plot de-interlacing
Overview
Mono-modal distances between scenes
Inspired by the classical unities of action, place and time in theater, we use three types of distance between scenes, based on three different modalities:
- Visual content for WHERE does take place action : Manhattan-like distance for HSV;
- Audio content for WHO is speaking : distance based on the count of common speakers between two scenes;
- Audio content for WHAT is said : cosine distance between TF-IDF words vectors from Automatic Speech Recognition.
Multi-modal gaussian distance
In order to get the most out of these three complementary modalities, we also define a multimodal Gaussian distance:
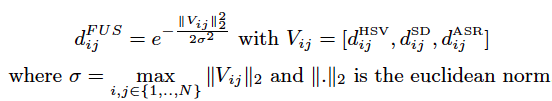
The use of the Gaussian kernel gives the opportunity to define clusters without a priori on shapes. This means that data that can not be easily separated in the original space can be clustered into homogeneous groups in the implicitly transformed high dimensional feature space.
Clustering approaches
We investigate the use of two clustering algorithms :
- an average-link agglomerative clustering processed on mono-modal distances;
- a spectral clustering processed on multi-modal distance.
The optimal number of clusters is defined by maximizing the affinity within clusters and minimizing the affinity betweens clusters.
Automatic detection of the most appropriate clustering depending of the tested data
Whatever the series, two types of episodes were found:
- episodes where separated sets of characters are involved in different stories and for which an average-link agglomerative clustering processed on speaker distance leads to the best results;
- episodes centered on a particular topic rather on different sets of characters and for which a spectral clustering processed on the multi-modal distance leads to the best results.
So we select the optimal clustering method depending of the automatically discovered type of the episode by using an undirected graph representing the social interactions between the characters of an episode.
The community detection is made by Louvain approach based on the maximization of the modularity (measure of the quality of the detected communities). A high modularity is related to separated sets of characters.
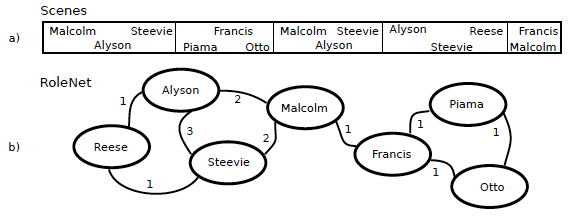
(a) List of characters for each scene. (b) Character social graph.
Application and Demo
We designed STOVIZ a web-based interface to illustrate the results of our plot de-interlacing approach, and to provide a tool for users willing to have a quick look at the narrative structure of an episode. Moreover, since both stories and scenes are subjective concepts, the evaluation of systems for automatic segmentation into scenes or stories is not straightforward. It is why StoViz also aims at helping this evaluation process by showing a graphical representation of the video, its manual scene or story segmentation, and the stories detected automatically. A numerical error rate (similar to the Diarization Error Rate used in speaker diarization) is thereby provided in order to quickly gain insight into the quality of the automatic approach.
Contributors
- Philippe Ercolessi
- Christine Sénac (contact)
- Philippe Joly (contact)
- Hervé Bredin (LIMSI)
Main publications
Philippe Ercolessi, Christine Senac, Hervé Bredin. StoViz: Story Vizualization of TV series (regular paper). Dans : ACM Multimedia, Nara, Japan, 29/10/12-02/11/12, (Eds.), ACM DL, p. 1329-1330, 2012. 

Philippe Ercolessi, Christine Senac, Hervé Bredin, Sandrine Mouysset. Hierarchical framework for TV series plot de-interlacing based on speakers, dialogues and images (regular paper). Dans : ACM Workshop on Audio and Multimedia Methods for Large-Scale Video Analysis, Nara, Japan, 29/10/12-02/11/12, (Eds.), Springer, p. 3-8, 2012. 

Philippe Ercolessi, Christine Senac, Hervé Bredin. Toward plot de-interlacing in TV series using scenes clustering (regular paper). Dans : International Workshop on Content-Based Multimedia Indexing (CBMI 2012), Annecy, France, 27/06/12-29/06/12, (Eds.), IEEE, (support électronique), juin 2012. 

Philippe Ercolessi, Christine Senac, Hervé Bredin, Sandrine Mouysset. Vers un résumé automatique de séries télévisées basé sur une recherche multimodale d’histoires. Dans : Revue des Sciences et Technologies de l’Information, Hermès Science, Vol. 15 N. 2, pp. 41-66,2012.