Singing Voice Detection
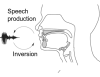
Context This research takes place in a context of audio indexing. After some work on the detection of speech and music, the problem of the position of singing appears. Actually, it is music produced by human voice. In our Speech/Music system, it is classifed mainly in the music category, but it was sometimes taken for speech. The purpose of this work